
This guide will give you an idea of how to become a Machine Learning Engineer. Note that Machine Learning Engineer positions tend to change from company to company, it especially depends on the scale of that company. Before we start, please note that the roadmap is opinionated, and you might have different opinions than those of the author. Having said that, I would love to hear your opinions and incorporate them in the roadmap if suitable. I
This roadmap is mainly for machine learning engineering rather than data science, but it’s best if you know the end-to-end model lifecycle and tools/frameworks/libraries you need to know to get the job and that includes data science frameworks as well. This roadmap is also oriented according to model lifecycle but the flow is the way you should learn these skills. This roadmap also focuses on machine learning engineering on supervised learning on tabular data as it is the most in-demand skill in the job market. I will start on machine learning on natural language processing, reinforcement learning and different domains later. I’ll also add links to my favorite learning sources.
Complete Roadmap
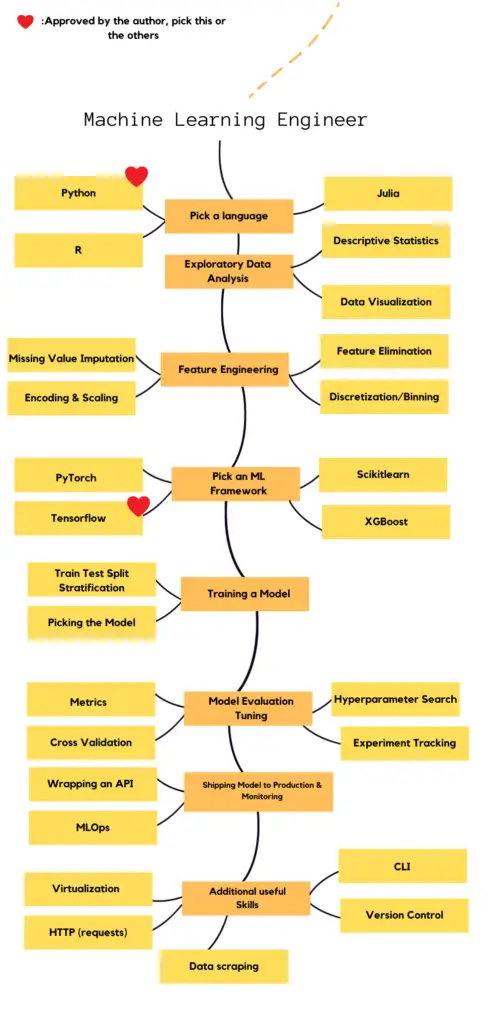
Below you will find the full version of the roadmap in a single image, and then you’ll find partial roadmaps with links to resources.
Broken Down Version
You will find the broken down version of the roadmap below and links to the resources to learn and master the frameworks/libraries.
Pick a Language
You can apply machine learning in multiple languages but most popular ones are Python, R, Julia and MATLAB. This guide is prepared for Python, but what you’re going to do through lifecycle is same. Most of the machine learning libraries are built for Python as it’s easy to learn by machine learning researchers who don’t have a coding background and people can use it as an extension for code written in other languages. I will add another roadmap for R later on that includes packages you can use. I personally don’t recommend MATLAB as it doesn’t have a wide community that you can debug with, it’s not open-source and it doesn’t give you the flexibility that others give.
Exploratory Data Analysis
Exploratory data analysis is a fundamental for every model lifecycle. You have to discover what’s going on in your data. If there’s a lot of sparsity within a feature, if your classes have imbalance, if there are many missing values, if there’s multicollinearity, you have to get rid of these during feature engineering part, but first you have to learn different types of visualizations and analyses. Don’t let these intimidate you, they’re easy to learn. You can use both matplotlib and seaborn, I do it often, but if you are a starter, I recommend you to learn matplotlib first. You have to learn pandas and numpy and get fluent in these for easy data manipulation.
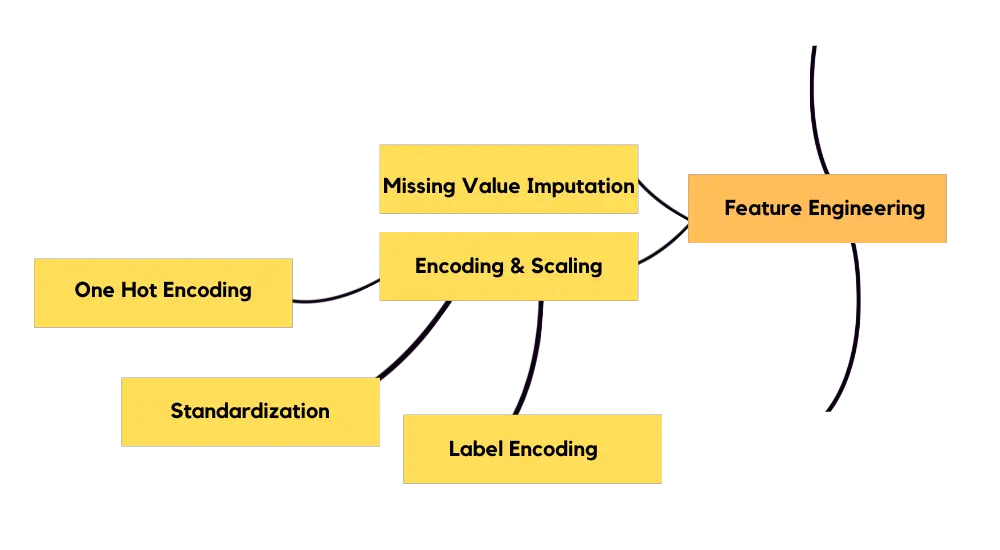
Feature Engineering
You need to apply missing value imputation. You need to determine whether you’ll get rid of a row or column depending on how much percent empty it is. There are few methods for missing value imputation, you can impute the mean of a column for instance. If you have a numerical column, you have to apply scaling. For your categorical values, you need to apply encoding.
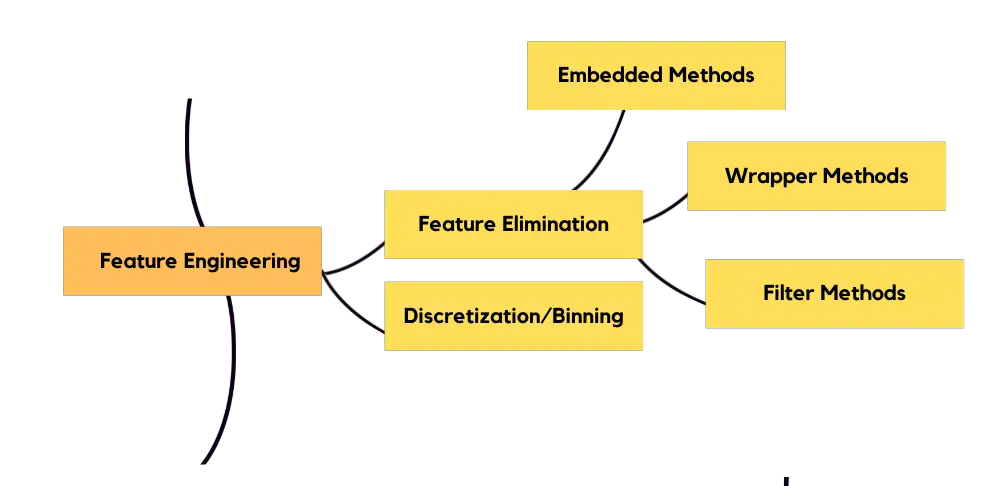
You need to discretize your data if needed. There’s a problem called curse of dimensionality and you need to get rid of some of your features for this, otherwise your model might be confused. There are various techniques:
- Embedded methods: Lasso regularization, ridge regularization and ElasticNet.
- Wrapper methods: Recursive feature elimination (RFE).
- Filter methods: Information gain, chi-square test, correlation test, Fisher score, LDA – ANOVA. You don’t need to learn all of these, in fact RFE and Chi-square test would suffice for starters. You can implement feature engineering with scikit-learn
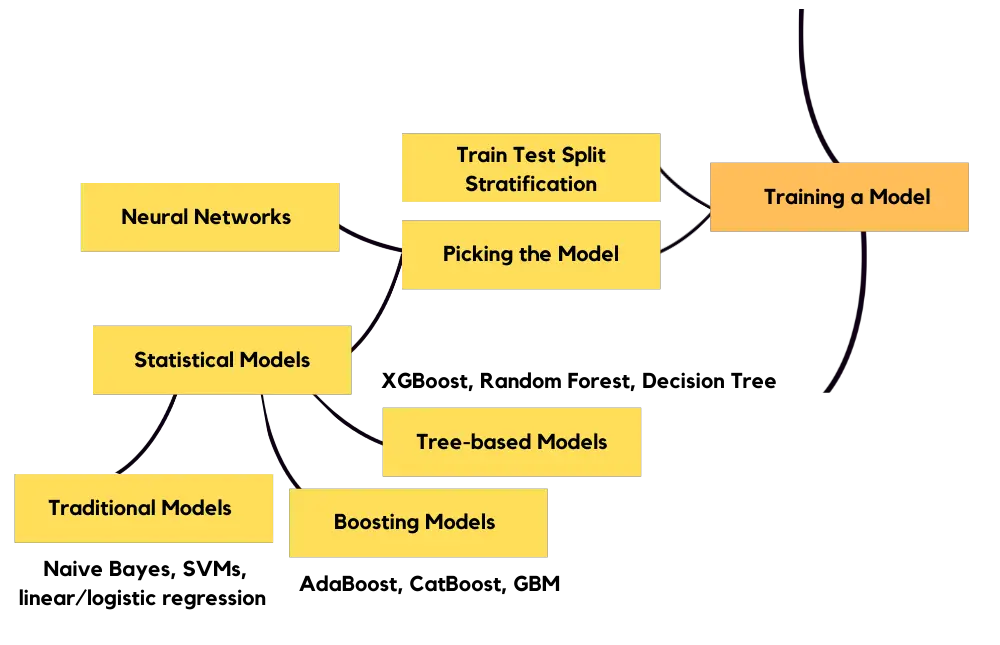
Model Training
After doing necessary feature engineering, you’ll be good to go for model training. It’s best if you learn statistical methods first to grasp the logic behind machine learning. Learning linear and logistic regression first is the best way to get started, then I’d suggest you to learn tree-based methods as they are the state-of-the-art methods for tabular data. Neural networks are overkill for beginners on tabular data. Statistical models can be found in sci-kitlearn. Tensorflow and PyTorch include neural network applications. Tensorflow also includes tree-based algorithms. Best way to get started is scikit-learn, tensorflow, and then pytorch.
Model Evaluation
You need to evaluate how your model performs through the metrics, depending on the problem you’re trying to solve. Classification and regression metrics are different. You’ll need to do cross validation of your model so that you can see if your model performs best across your data.
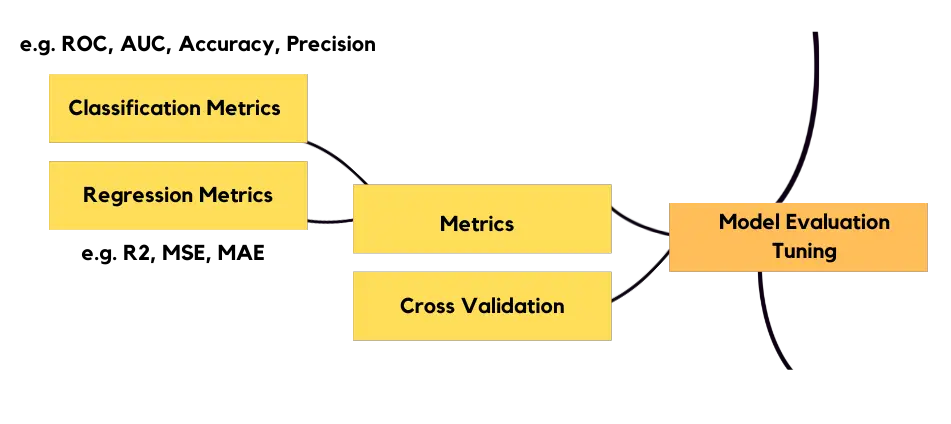
Your model will take different hyperparameters, you’ll need to optimize your hyperparameters using different searching techniques, like Grid Search and Randomized Search. During model evaluation you need to track your experiments and keep them organized. There are different frameworks for these, you can pick one of them, totally up to you.
Shipping Model to Production & Monitoring
Majority of machine learning engineers in smaller companies are also responsible for shipping their models to production and for this, you can use Flask or Django. The difference between two is that Django is an all-in-one framework meanwhile Flask gives you flexibility, it’s like playing with lego blocks, that’s why Flask is better for starters. You also need to know about model monitoring, as model lifecycle doesn’t end at shipping model to production, you have to observe your model for potential data drifts. Good thing about Comet is you can use it for both experiment tracking and model monitoring. However, you can learn these later as these are advanced parts rather than starters.
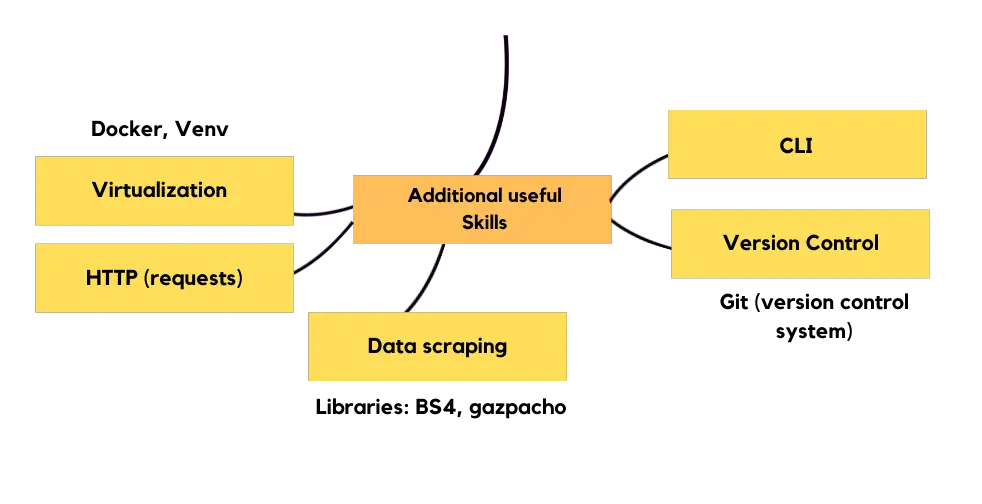
Additional useful Skills
The most essential two skills in machine learning engineering (other than model lifecycle) are virtualization of your model for production and version control. If you are a starter, you can use virtual environments (conda, pyenv, python environment or pipenv), my personal favorite is pyenv. To get a better hold of what you’re doing, I suggest you to learn command line interface. I personally found HTTP requests (someone to get a prediction from your model) to be a good skill to have in your toolkit, also learn async if you have room for learning as you’ll put your prediction requests in queue. Data scraping with libraries like BeautifulSoup and gazpacho is useful for when you need additional data or you want to have a personal project for your portfolio.
Ping Me
For any suggestions, improvements and feedback, feel free to submit an issue or reach out to me on twitter @mervenoyann.
