

20 Best Big Data Tools and Software That You Can Use
In our old days, we traveled from one city to another using a horse cart. However, nowadays is it possible to go using a horse cart? Obviously no, it is quite impossible right now. Why? Because of the growing population and the length of time. In the same way, Big Data emerges from such an idea. In this current technology-driven decade, data is growing too fast with the rapid growth of social media, blogs, online portals, website, and so forth. It is impossible to store these massive amounts of data traditionally. As a consequence, thousands of Big Data tools and software are proliferating in the data science world gradually. These tools perform various data analysis tasks, and all of them provide time and cost efficiency. Also, these tools explore business insights that enhance the effectiveness of business.
With the exponential growth of data, numerous types of data, i.e., structured, semi-structured, and unstructured, are producing in a large volume. As an instance, only Walmart manages more than 1 million customer transactions per hour. Therefore, to manage these growing data in a traditional RDBMS system quite impossible. Additionally, there are some challenging issues to handle this data, including capturing, storing, searching, cleansing, etc. Here, we outline the top 20 best Big Data software with their key features to boost your interest in big data and develop your Big Data project effortlessly.
1. Hadoop

Apache Hadoop is one of the most prominent tools. This open source framework permits reliable distributed processing of large volume of data in a dataset across clusters of computers. Basically, it is designed for scaling up single servers to multiple servers. It can identify and handle the failures at the application layer. Several organizations use Hadoop for their research and production purpose.
Features
- Hadoop consists of several modules: Hadoop Common, Hadoop Distributed File System, Hadoop YARN, Hadoop MapReduce.
- This tool makes data processing flexible.
- This framework provides efficient data processing.
- There is an object store named Hadoop Ozone for Hadoop.
2. Quoble
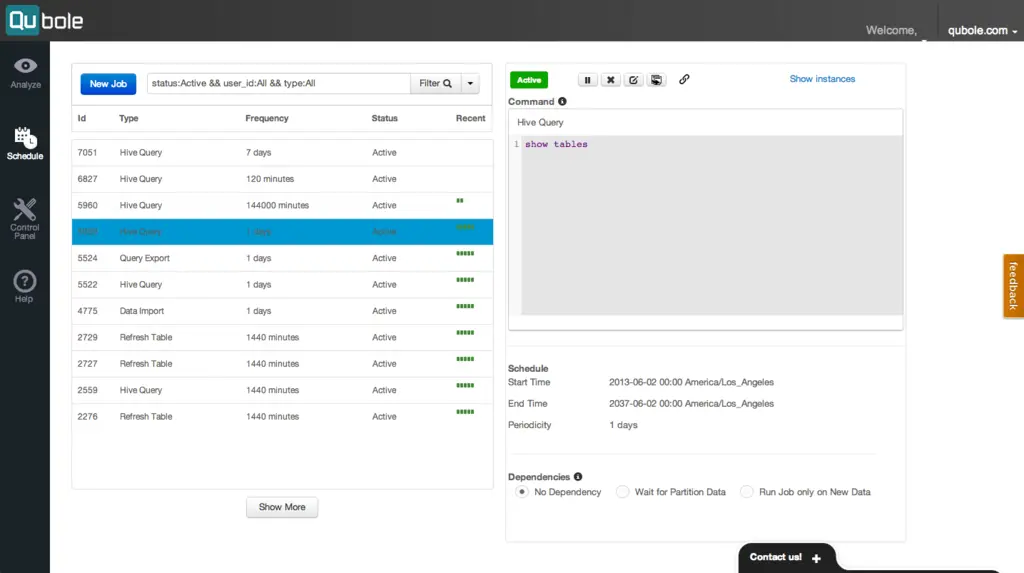
Quoble is the cloud-native data platform which develops machine learning model at an enterprise scale. The vision of this tool is to focus on data activation. It permits to process all type of datasets to extract insights and build artificial intelligence based applications.
Features
- This tool allows easy to use end-user tools, i.e., SQL query tools, notebooks, and dashboards.
- It provides a single shared platform that enables users to drive ETL, analytics, and artificial intelligence and machine learning applications more efficiently across open source engines like Hadoop, Apache Spark, TensorFlow, Hive and so forth.
- Quoble accommodates comfortably with new data on any cloud without adding new administrators.
- It can minimize the big data cloud computing cost by 50% or more.
3. HPCC
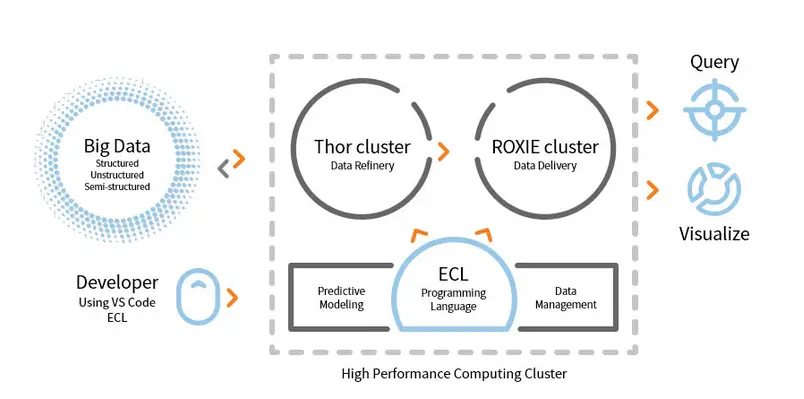
LexisNexis Risk Solution develops HPCC. This open source tool provides a single platform, single architecture for data processing. It is easy to learn, update, and program. Additionally, easy to integrate data and manage clusters.
Features
- This data analysis tool enhances scalability and performance.
- ETL engine is used for extraction, transformation, and loading data using a scripting language named ECL.
- ROXIE is the query engine. This engine is an index based search engine.
- In data management tools, data profiling, data cleansing, job scheduling are some features.
4. Cassandra

Do you need a big data tool which will you provide scalability and high availability as well as excellent performance? Then, Apache Cassandra is the best choice for you. This tool is a free, open source, NoSQL distributed database management system. For its distributed infrastructure, Cassandra can handle a high volume of unstructured data across commodity servers.
Features
- Cassandra follows no single point of failure (SPOF) mechanism that means if the system fails, then the entire system will stop.
- By using this tool, you can get robust service for clusters spanning multiple data-centers.
- Data is replicated automatically for fault tolerance.
- This tool applies to such applications that are not able to lose data, even if the data center is down.
5. MongoDB

This Database Management tool, MongoDB, is a cross-platform document database that provides some facilities for querying and indexing such as high performance, high availability, and scalability. MongoDB Inc. develops this tool and licensed beneath the SSPL (Server Side Public License). It works on the idea of collection and document.
Features
- MongoDB stores data using JSON- like documents.
- This distributed database provides availability, horizontally scaling, and distribute geographically.
- The features: ad hoc query, indexing, and aggregation in real-time provide such a way to access and analyze data potentially.
- This tool is free to use.
6. Apache Storm

Apache Storm is one of the most accessible big data analysis tools. This open source and free distributed real-time computational framework can consume the streams of data from multiple sources. Also, its process and transform these streams in different ways. Additionally, it can incorporate with the queuing and database technologies.
Features
- Apache Storm is easy to use. It can easily integrate with any programming language.
- It is fast, scalable, fault-tolerant, and give assurance that your data will be easy to set up, operate, and process.
- This computation system has several use cases, including ETL, distributed RPC, online machine learning, real-time analytics, and so forth.
- The benchmark of this tool is that it can process over a million tuples per second per node.
7. CouchDB

The open source database software, CouchDB, was explored in 2005. In 2008, it became a project of Apache Software Foundation. For the main programming interface, it uses the HTTP protocol, and multi-version concurrency control (MVCC) model is used for concurrency. This software is implemented in the concurrency-oriented language Erlang.
Features
- CouchDB is a single node database which is more suitable for web applications.
- JSON is used to store data and JavaScript as its query language. The JSON based document format can be easily translated across any language.
- It is compatible with platforms, i.e., Windows, Linux, Mac-ios, etc.
- User-friendly interface is available for insertion, update, retrieval, and deletion of a document.
8. Statwing

Statwing is an easy-to-use and efficient data science as well as a statistical tool. It was built for big data analysts, business users, and market researchers. The modern interface of it can do any statistical operation automatically.
Features
- This statistical tool can explore data in second.
- It can translate the outcomes into plain English text.
- It can create histograms, scatterplots, heatmaps, and bar charts and also can export to Microsoft Excel or PowerPoint.
- It can clean data, explore relationships, and create charts effortlessly.
9. Flink

The open source framework, Apache Flink, is a distributed engine of stream processing for stateful computation over data. It can be bounded or unbounded. The fantastic specification of this tool is that it can be run in all known cluster environments like Hadoop YARN, Apache Mesos, and Kubernetes. Also, it can perform its task at in memory speed and at any scale.
Features
- This big data tool is fault tolerant and can recover its failure.
- Apache Flink supports a variety of connectors to third-party systems.
- Flink allows flexible windowing.
- It provides several APIs at different levels of abstraction and also it has libraries for common use cases.
10. Pentaho

Do you need a software which can access, prepare, and analyze any data from any source? Then, this trendy data integration, orchestration, and business analytics platform, Pentaho is the best choice for you. The motto of this tool is to turn big data into big insights.
Features
- Pentaho permits to check data with easy access to analytics, i.e., charts, visualizations, etc.
- It supports a wide range of big data sources.
- No coding is required. It can deliver the data effortlessly to your business.
- It can access and integrate data for data visualization effectively.
11. Hive

Hive is an open source ETL(extraction, transformation, and load) and data warehousing tool. It is developed over the HDFS. It can perform several operations effortlessly like data encapsulation, ad-hoc queries, and analysis of massive datasets. For data retrieval, it applies the partition and bucket concept.
Features
- Hive acts as a data warehouse. It can handle and query only structured data.
- The directory structure is used to partition data to enhance the performance on specific queries.
- Hive supports four types of file formats: textfile, sequencefile, ORC, and Record Columnar File (RCFILE).
- It Supports SQL for data modeling and interaction.
- It allows custom User Defined Functions(UDF) for data cleansing, data filtering, etc.
12. Rapidminer
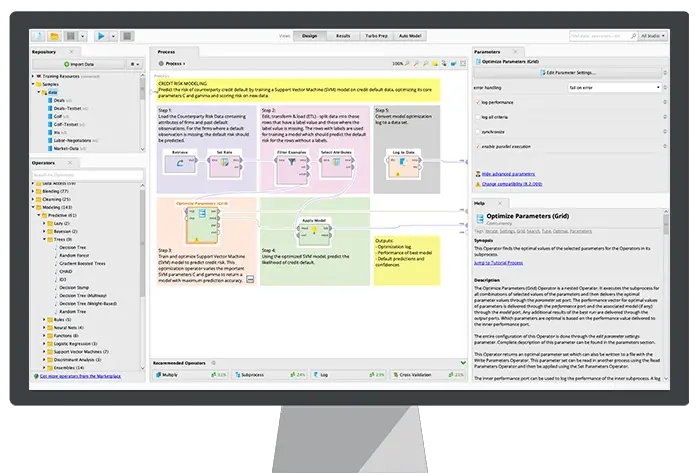
Rapidminer is an open source, fully transparent, and an end-to-end platform. This tool is used for data prep, machine learning, and model development. It supports multiple data management techniques and permits many products to develop new data mining processes and build predictive analysis.
Features
- It helps to store streaming data to various databases.
- It has interacting and shareable dashboards.
- This tool supports machine learning steps like data preparation, data visualization, predictive analysis, deployment, and so forth.
- It supports the client-server model.
- This tool is written in Java and provides a graphical user interface (GUI) to design, and execute workflows.
13. Cloudera
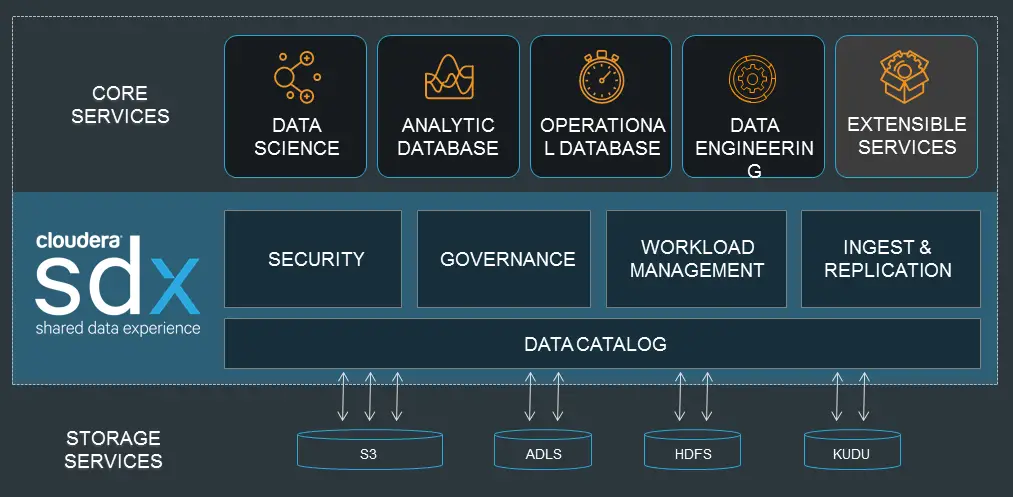
Are you searching a highly secure big data platform for your big data project? Then, this modern, fastest, and most accessible platform, Cloudera is the best option for your project. Using this tool, you can get any data across any environment within a single and scalable platform.
Features
- It provides real-time insights for monitoring and detection.
- This tool spins up and terminate clusters, and only pay for what is needed.
- Cloudera develops and trains data model.
- This modern data warehouse delivers an enterprise-grade and hybrid cloud solution.
14. DataCleaner
The data profiling engine, DataCleaner, is used to discovering and analyzing the quality of data. It has some splendid features like supports HDFS datastores, fixed-width mainframe, duplicate detection, data quality ecosystem, and so forth. You can use its free trial.
Features
- DataCleaner has user-friendly and explorative data profiling.
- Ease of configuration.
- This tool can analyze and discover the quality of the data.
- One of the benefits of using this tool is that it can enhance the inferential matching.
15. Openrefine
Are you searching a tool for handling messy data? Then, Openrefine is for you. It can work with your messy data and clean them and transform them into another format. Also, it can integrate these data with web services and external data. It is available in several languages including Tagalog, English, German, Filipino, and so forth. Google News Initiative supports this tool.
Features
- Able to explore a massive amount of data in a large dataset.
- Openrefine can extend and link the datasets with web services.
- Can import various formats of data.
- It can perform advanced data operations using Refine Expression Language.
16. Talend
The tool, Talend, is an ETL (extract, transform, and load) tool. This platform provides services for data integration, quality, management, Preparation, etc. Talend is the only ETL tool with plugins to integrate with the ecosystem of big data effortlessly and effectively.
Features
- Talend offers several commercial products such as Talend Data Quality, Talend Data Integration, Talend MDM (Master Data Management) Platform, Talend Metadata Manager, and many more.
- It permits Open Studio.
- The required operating system: Windows 10, 16.04 LTS for Ubuntu, 10.13/High Sierra for Apple macOS.
- For data integration, there are some connectors and components in Talend Open Studio: tMysqlConnection, tFileList, tLogRow, and many more.
17. Apache SAMOA
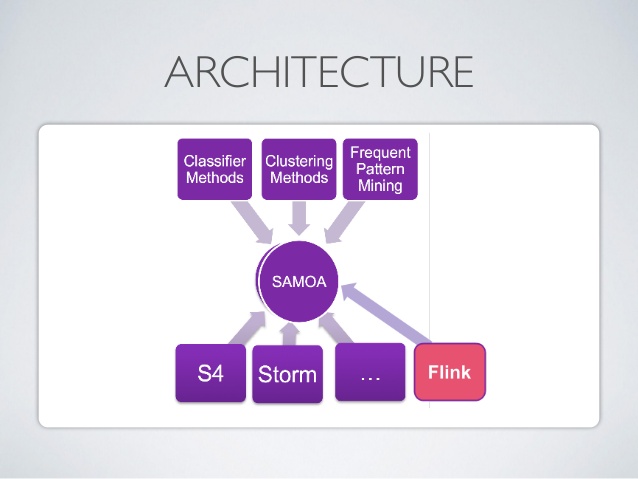
Apache SAMOA is used for distributed streaming for data mining. This tool is also used for other machine learning tasks, including classification, clustering, regression, etc. It runs on the top of DSPEs (Distributed Stream Processing Engines). It has a pluggable structure. Furthermore, it can run on several DSPEs, i.e., Storm, Apache S4, Apache Samza, Flink.
Features
- The amazing feature of this big data tool is that you can write a program once and run everywhere.
- There is no system downtime.
- No backup is needed.
- The infrastructure of Apache SAMOA can be used again and again.
18. Neo4j

Neo4j is one of the accessible Graph Databases and Cypher Query Language (CQL) in the big data world. This tool is written in Java. It provides a flexible data model and gives output based on real-time data. Also, the retrieval of connected data is faster than other databases.
Features
- Neo4j provides scalability, high-availability, and flexibility.
- The ACID transaction is supported by this tool.
- To store data, it does not need a schema.
- It can be incorporated with other databases seamlessly.
19. Teradata
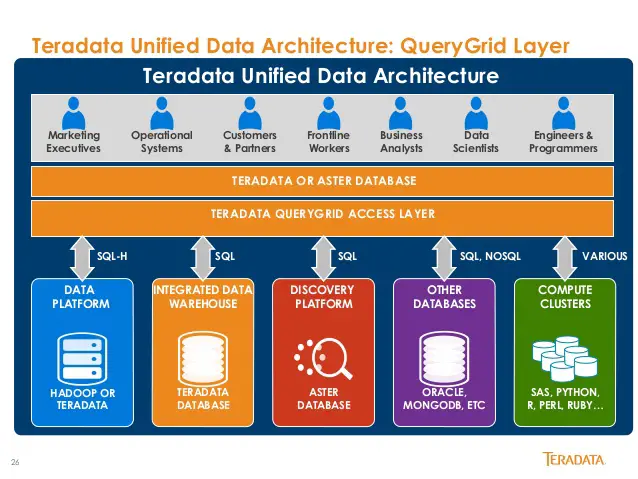
Do you need a tool for developing large scale data warehousing application? Then, the well known relational database management system, Teradata is the best option. This system offers end-to-end solutions for data warehousing. It is developed based on the MPP (Massively Parallel Processing) Architecture.
Features
- Teradata is highly scalable.
- This system can connect network-attached systems or mainframe.
- The significant components are a node, parsing engine, the message passing layer, and the access module processor (AMP).
- It supports industry-standard SQL to interact with the data.
20. Tableau
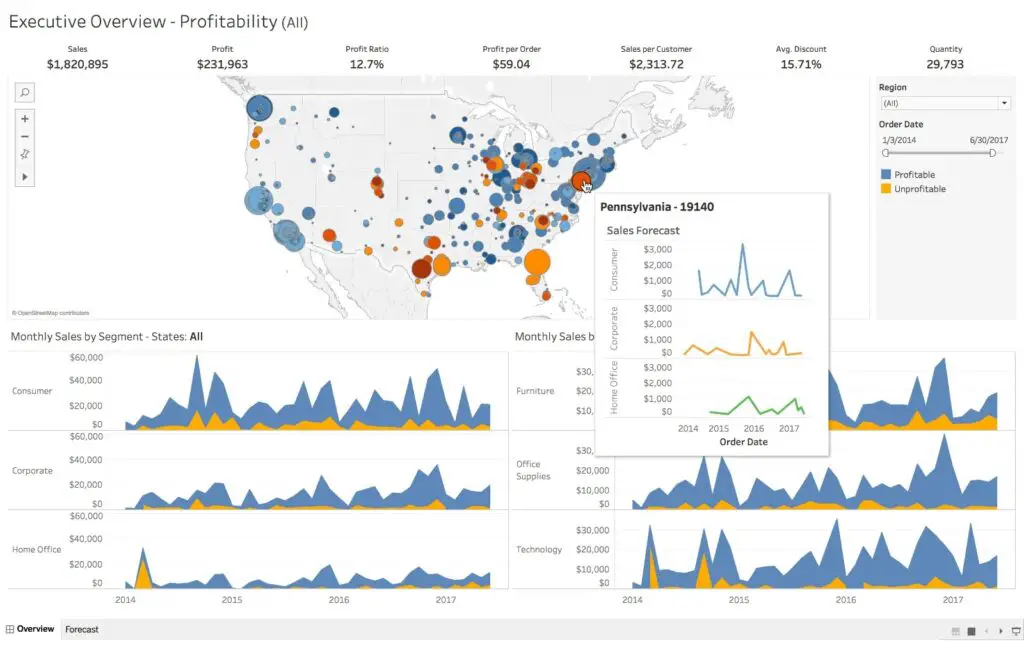
Are you searching for an efficient data visualization tool? Then, Tabelu comes here. Basically, the primary objective of this tool is to focus on business intelligence. Users no need to write a program to create maps, charts, and so forth. For live data in the visualization, recently they explored web connector to connect the database or API.
Features
- Tabelu does not require complicated software setup.
- Real-time collaboration is available.
- This tool provides a central location to delete, manage schedules, tags, and change permissions.
- Without any integration cost, it can blend various datasets, i.e., relational, structured, etc.
Finally
Big Data is a competitive edge in the world of modern technology. It is becoming a booming field with lots of career opportunities. A vast number of potential information is generated by using Big Data technique. Therefore, organizations depend on Big Data to use this information for their further decision making as it is cost effective and robust to process and manage data. Most of the Big Data tools provide a particular purpose. Here, we narrate the best 20, and hence, you can choose your one as needed.