


Preface
Fuzzing technology is an unavoidable topic in the field of vulnerability mining, and Wuheng Lab has been using fuzzing technology to find product problems. Although fuzzing is not a panacea, it is absolutely impossible without it. To say that it is not a panacea is actually a relative term. In an ideal state, for example, within an acceptable time frame, with sufficient computing resources and sufficiently low system complexity, fuzzing can give you any desired result. This is like asking a computer to print some text randomly. As long as the time is long enough and the efficiency of random character generation is fast enough, a “Three Body” will be printed out sooner or later.
However, the theory is full, and the reality is skinny. Although the computing resources and efficiency of human society are constantly increasing, the complexity of software systems is increasing at a faster rate. In the past, loopholes can be found through dumb fuzz. The situation is almost extinct. Therefore, the fuzzing technology must develop in the direction of sample generation with higher coverage, more efficient code path movement algorithms (mutations), and more reasonable allocation and scheduling of computing resources.
I dare not pretend to what extent fuzzing technology can develop in the future. It depends on the joint efforts of academia and industry. But if we see an AI that can solve bugs by itself when facing most unknown systems, then There is no doubt that it must use fuzzing! That’s the end of the sentimental part, let’s down-to-earth practice how to fuzz some native binary of Android.
technical background:
There are many genres of fuzzing binary at present, but they are all the same. The purpose is to generate samples at the fastest speed to cover more code paths. Obviously, it is the most scientific to use code coverage as the driving direction of the entire fuzzer in this process, which is to cover CGF (Coverage-based Greybox Fuzzing) is the rate-guided gray box fuzzing technology. It is necessary to introduce this core technology background.
There are usually the following methods for statistical coverage information:
1. Compiler Instrumentation: If the source code exists, this method is the most reliable and efficient way to do code coverage statistics and fuzzing, such as using LLVM, GCC, etc., but unfortunately the source code is not available in many cases.
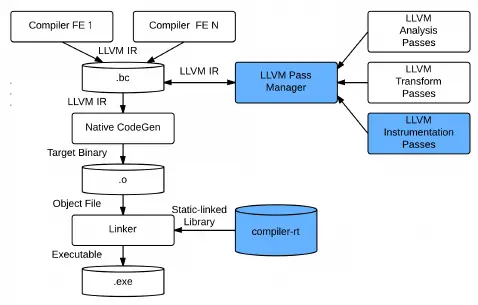
https://gcc.gnu.org/onlinedocs/gcc/Instrumentation-Options.html https://llvm.org/docs/CommandGuide/llvm-cov.html
2. Execute Simulation: For example, AFL based on QEMU and Unicorn mode will insert coverage statistics code before QEMU is ready to translate and execute basic blocks. The disadvantage is that the execution efficiency is a bit low.
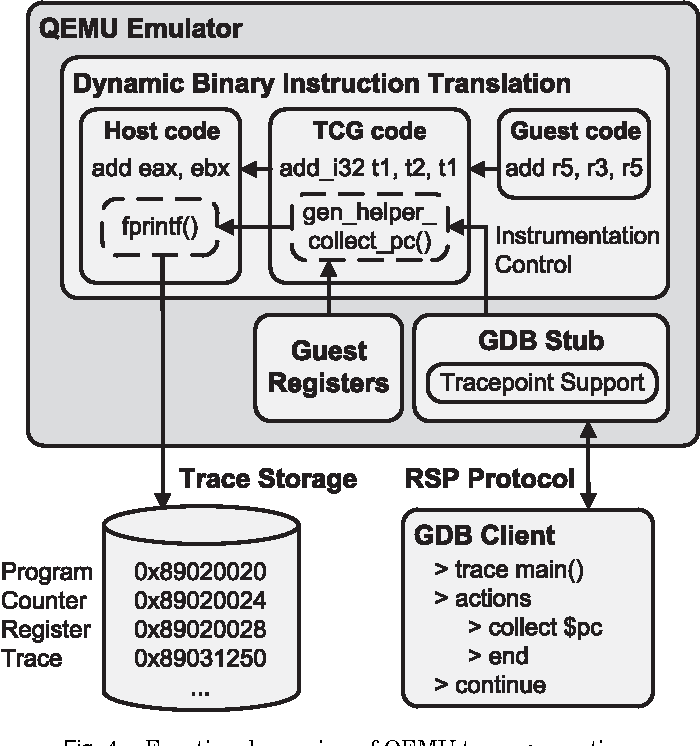
https://github.com/edgarigl/qemu-etrace
https://andreafioraldi.github.io/articles/2019/07/20/aflpp-qemu-compcov.html
3. Runtime Trace: This form of code path coverage is more flexible, and the implementation form is also more diversified. It is also the main method used in this article. The more common methods such as using frida dynamic instrumentation, debugging startup, or directly modifying the mobile phone ROM can be implemented. The disadvantage is that it is difficult to guarantee the stability of the structure due to the complexity of the structure. In many cases, the fuzzer itself crashes before the target crash. The frida stalker tool used will be introduced in detail later in the article.
https://frida.re/docs/stalker/
4. Binary Rewrite: This method is mainly to instrument each basic statement block of binary disassemble. If it is done ideally, the effect may be second only to Compiler Instrumentation, but the disadvantage is that it is too difficult, if it is only relatively simple The binary problem is not big, but if it is a highly complex system, it will be difficult to implement. For example, some binary has its own VM, the binary has its own mechanism of runtime rewrite, and the binary uses some special Architecture Feature of the CPU. , Various binary relocation problems, etc., if these are not handled well, rewriten binary cannot be executed smoothly.
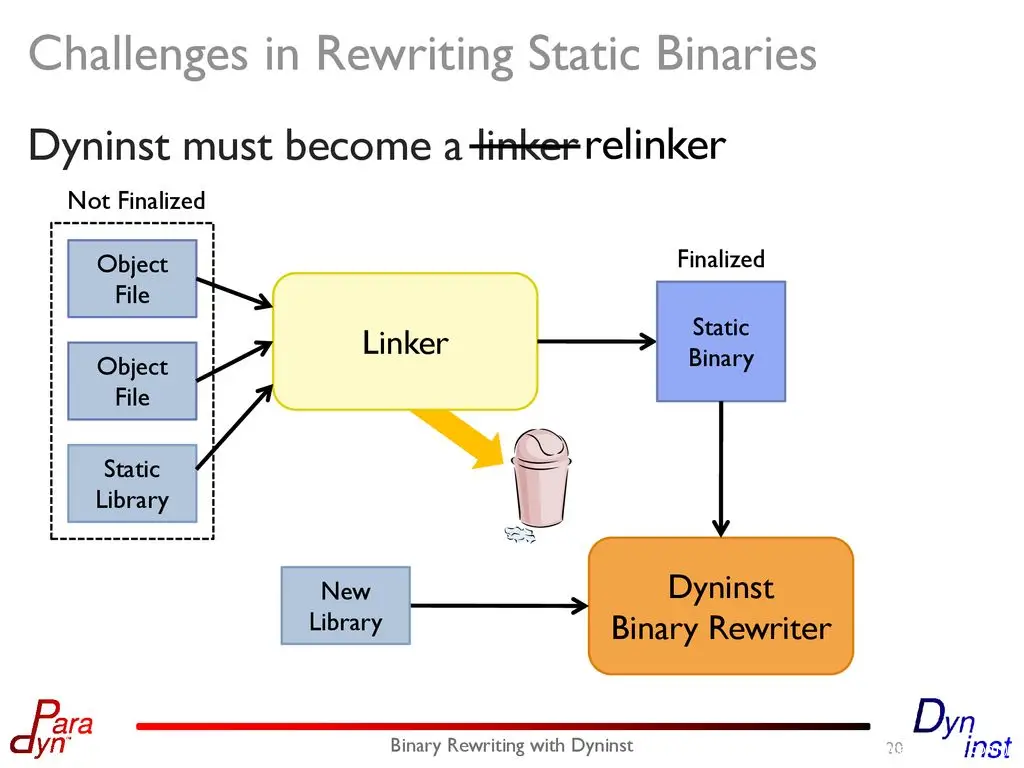
https://github.com/GJDuck/e9patch https://github.com/utds3lab/multiverse https://github.com/talos-vulndev/afl-dyninst
5. Hardware Trace: This may become the mainstream direction of binary fuzzing in the future. Hardware and software are naturally in God’s perspective. Here we need to clarify the category of Hardware Trace that I am talking about. It does not really need to be dedicated to fuzzing. Hardware, here is mainly to use the ability of the layer between the hardware and the operating system to complete the purpose of fuzz, which is especially effective for the fuzz operating system itself, such as the ability to use hypervisors, hardware debuggers, etc., of course, it is not ruled out. One day someone will come up with an FPGA or even an ASIC to run fuzz, haha, that’s too hard core!
https://github.com/gamozolabs/applepie https://the-elves.github.io/Ajinkya-GSoC19-Submission/
Target selection:
Regarding how to choose a fuzzing target, I mainly share my experience and ideas from the perspective of the security risk of the Android so library:

1. There is an attack surface: This is the first point to be confirmed. Although in theory, any program has an attack surface, but there are large and small, and more or less. We tend to choose targets with a large attack surface. It is more valuable. For example, some so libraries may directly receive the user’s external data for processing, such as video players, image parsing engines, js parsing engines, etc. If these so libraries have loopholes, it is likely to be easier to use directly.
2. High-frequency applications: The so libraries that are used more frequently are also worthy of key consideration. The more frequently used, the easier to attack and use, and the greater the risk. For example, some tools are util-type so libraries. It may be called by many other libraries, and the probability of problems is high.
3. High complexity: Theoretically, the probability of loopholes is proportional to the complexity of the system. The more complex, the easier it is to cause problems.
4. Absence of mitigation measures: Some so libraries may not take security into consideration during the compilation process, and the safe compilation option is not turned on, which will lead to the vulnerability of it being easy to be exploited and the risk is also high.
Sample generation:

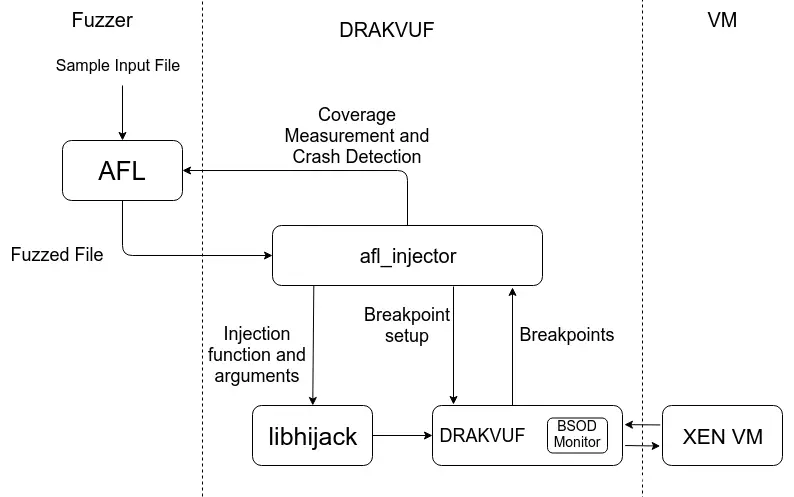
After confirming the goal, we must start to consider the business logic of the goal. The more clearly we can understand the test goal, the more accurately we can construct a good sample and improve the efficiency of fuzzing. This process is like the guidance process of a missile before hitting the target. It is necessary to clarify the various paths and obstacles that need to be bypassed to hit the target. To implement the business, you need to understand what kind of input data the target will receive, what is the process of data processing, whether interaction is required, whether it is synchronous or asynchronous, etc. The more accurate and clear the better. For example, if the target of fuzzing is the H265 decoding algorithm of a video decoding engine, then it is necessary to consider how to generate some video samples based on the H265 encoding algorithm. If the samples use other encodings such as MPEG, AVS, WMV, etc., it may be fuzzed. You may not be able to find out a problem with the H265 decoder when you are too old.
After “precision guidance” we also need to do something similar to “fire coverage”, because it is difficult to maximize code coverage by generating a single sample, so we need to make some diversified changes within the target receiving data range. Generate a sample set, and achieve a satisfactory code coverage through a large number of diverse samples.
This article uses the ffmpeg library to generate H265 video samples, and some code logic is sampled.
Make some random changes to the original frame:

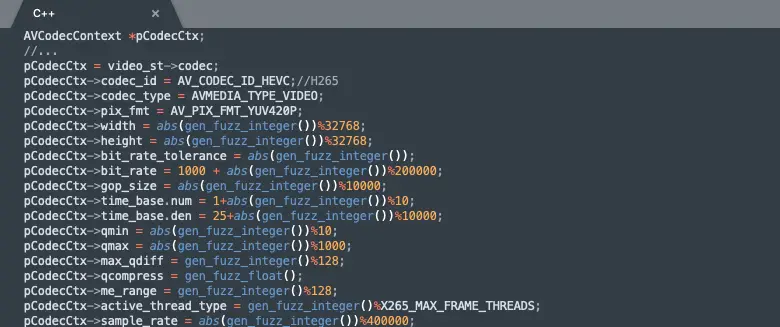
Video parameters are also randomly and diversified settings:
You can also optionally do something before encapsulating the video stream:
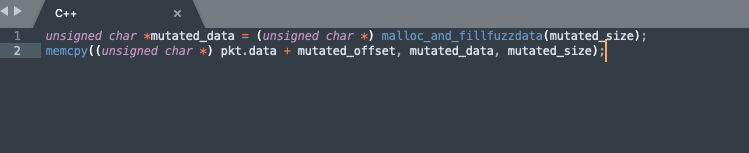
The video file generated in this way has actually undergone a certain degree of mutation, and even some crashes can be directly fuzzed.
Coverage guide:
The sample set is available, we need to do some tailoring work, mainly based on the sample to screen the coverage of the tested target, select the smallest set that can maximize the coverage, and then mutate this smallest sample set, so as to avoid generating some Repetitive test cases.
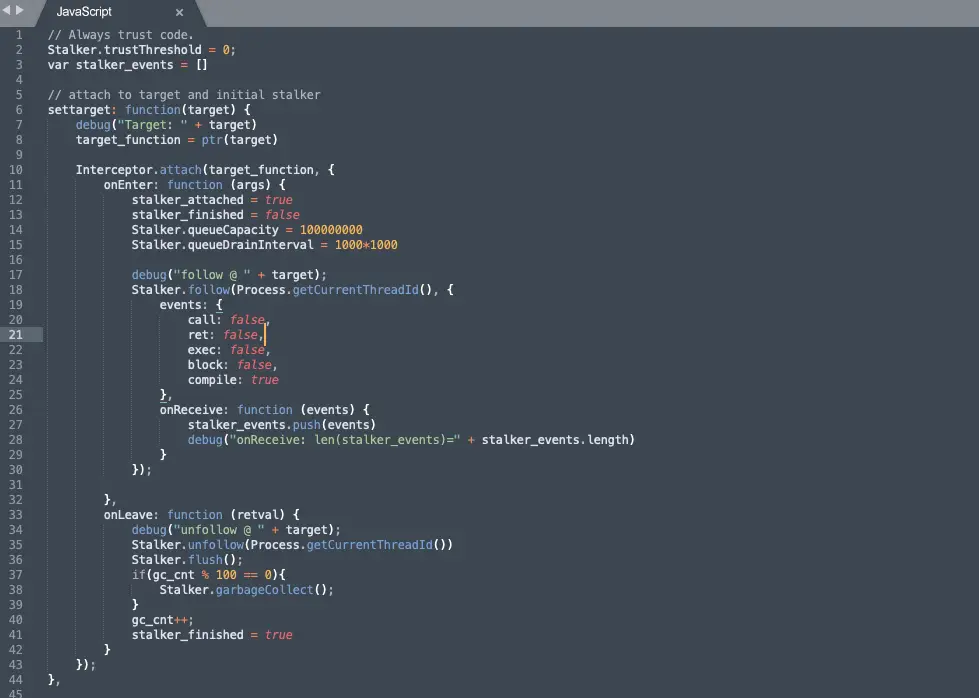
The stalker mentioned in the technical background is the core of this link. The stalker is the code tracer of the frida series of artifacts, which can achieve code tracing at the function level, basic block level, and instruction set. However, this tool has not been good enough for arm support, and the current version of frida 14.0 only supports arm64.
The main principle of stalker is dynamic recompilation. Here we briefly introduce some concepts of proper nouns in stalker:
Blocks: Basic blocks, the concept is the same as in the compilation principle, so I won’t repeat them.
Probes: Probes is a pile of basic blocks, if you have used interceptor, they are very similar.
Trust Threshold: This concept is a bit convoluted. It is actually mainly for optimizing the efficiency of compilation and execution, but setting it is related to some programs with self-modifying functions, such as some binaries that have been shelled or made anti-disassembly. During runtime, it will rewrite its own code. In this process, the stalker must perform dynamic recompilation of the code again, which will be a very time-consuming and troublesome process. So stalker sets a threshold N for blocks. After blocks are executed N times, the block will be marked as trusted and will not be modified in the future.
After understanding these concepts, continue to look at the basic operations of stalker in the process of dynamic recompilation. The stalker will apply for a block of memory, write the instrumented block copy in the unit of basic block and insert Probes, relocate the position-related instructions such as ADR Address of label at a PC-relative offset. For function calls, save the context related to lr Information, establish the index of this block and count the count, if it reaches the set threshold of Trust Threshold, no recompilation will be performed. Next, a basic block will be executed and the next one will continue. Due to space limitations, this process can only be generalized. The actual processing process is more complicated. Interested students can read the code of stalker to deepen their understanding.

Through the ability of stalker, we can clearly get the coverage during the trace target process, and then use the coverage to optimize the sample set and guide the mutation process. For example, we can record the coverage status by establishing a bitmap, filter the samples according to the coverage level, and use the coverage to determine the effect of each sample mutation.
Finally, cut down a few key code examples:
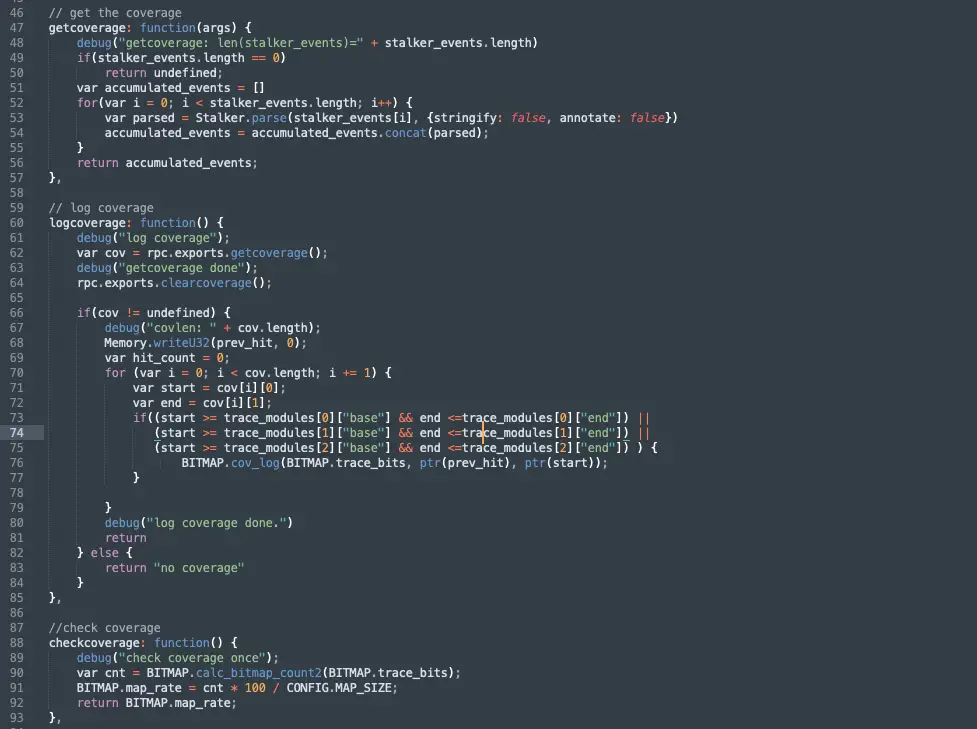
Conclusion:
As a classic method of vulnerability mining, fuzzing technology has always been loved by security practitioners. Wuheng Labs has also been committed to using fuzzing technology to discover product security defects and improve product quality. In this process, we found a lot of security and stability problems, but the road is long and long. In the future, Wuheng Laboratory will continue to invest in research in the direction of intelligence, efficiency, and precision of fuzzing, and to the industry Contribute results.