


Table of Contents
- 1. Kuiper
- 1.1. What is Kuiper?
- 1.2. Why Kuiper?
- 1.3. How Kuiper Will Help Optimize the Investigation?
- 1.4. Use Cases
- 2. Examples
- 3. Kuiper Components
- 3.1. Components Overview
- 3.2. Parsers
- 4. Getting Started
- 4.1. Requirements
- 4.1. Installation
- 5. Issues Tracking and Contribution
- 6. Licenses
- 7. Authors
Kuiper
Digital Investigation Platform
What is Kuiper?
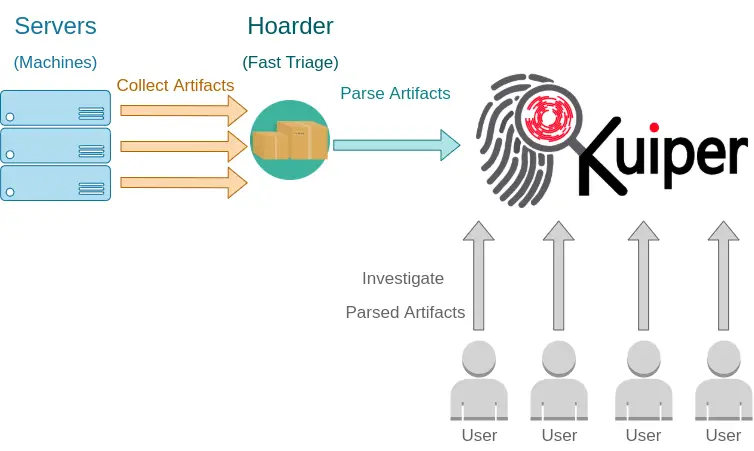
Kuiper is a digital investigation platform that provides a capabilities for the investigation team and individuals to parse, search, visualize collected evidences (evidences could be collected by fast traige script like Hoarder). In additional, collaborate with other team members on the same platform by tagging artifacts and present it as a timeline, as well as setting rules for automating the detection. The main purpose of this project is to aid in streamlining digital investigation activities and allow advanced analytics capabilities with the ability to handle a large amounts of data.
Why Kuiper?
Today there are many tools used during the digital investigation process, though these tools help to identify the malicious activities and findings, as digital analysts there are some shortages that needs to be optimized:
- Speeding the work flow.
- Increase the accuracy.
- Reduce resources exhaustion.
With a large number of cases and a large number of team members, it becomes hard for team members collaboration, as well as events correlation and building rules to detect malicious activities. Kuiper solve these shortages.
How Kuiper Will Help Optimize the Investigation?
- Centralized server: Using a single centralized server (Kuiper) that do all the processing on the server-side reduce the needed hardware resources (CPU, RAM, Hard-disk) for the analysts team, no need for powerful laptop any more. In addition, all evidences stored in single server instead of copying it on different machines during the investigation.
- Consistency: Depending on different parsers by team members to parse same artifacts might provide inconsistency on the generated results, using tested and trusted parsers increases the accuracy.
- Predefined rules: Define rules on Kuiper will save a lot of time by triggering alerts on past, current, and future cases, for example, creating rule to trigger suspicious encoded powershell commands on all parsed artifacts, or suspicous binary executed from temp folder, within Kuiper you can defined these rules and more.
- Collaboration: Browsing the parsed artifacts on same web interface by team members boost the collaboration among them using tagging and timeline feature instead of every analyst working on his/her own machine.
Use Cases
- Case creation: Create cases for the investigation and each case contain the list of machines scoped.
- Bulk evidences upload: Upload multiple files (artifacts) collected from scoped machines via Hoarder, KAPE, or files collected by any other channel.
- Evidence processing: Start parsing these artifact files concurrently for selected machines or all.
- Holistic view of evidences: Browse and search within the parsed artifacts for all machines on the opened case.
- Rules creation: Save search query as rules, these rules could be used to trigger alerts for future cases.
- Tagging and timeline: Tag suspicious/malicious records, and display the tagged records in a timeline. For records or information without records (information collected from other external sources such as FW, proxy, WAF, etc. logs) you can add a message on timeline with the specific time.
- Parsers management: Collected files without predefined parser is not an issue anymore, you can write your own parser and add it to Kuiper and will parse these files. read more how to add parser from Add Custom Parser
Examples
Create cases and upload artifacts
Investigate parsed artifacts in Kuiper
Kuiper Components
Components Overview
Kuiper use the following components:
- Flask: A web framework written in Python, used as the primary web application component.
- Elasticsearch: A distributed, open source search and analytics engine, used as the primary database to store parser results.
- MongoDB: A database that stores data in JSON-like documents that can vary in structure, offering a dynamic, flexible schema, used to store Kuiper web application configurations and information about parsed files.
- Redis: A in-memory data structure store, used as a database, cache and message broker, used as a message broker to relay tasks to celery workers.
- Celery: A asynchronous task queue/job queue based on distributed message passing, used as the main processing engine to process relayed tasks from redis.
- Gunicorn: Handle multiple clients HTTPs requests
Getting Started
Requirements
- OS: 64-bit Ubuntu 18.04.1 LTS (Xenial) (preferred)
- RAM: 4GB (minimum), 64GB (preferred)
- Cores: 4 (minimum)
- Disk: 25GB for testing purposes and more disk space depends on the amount of data collected.
Notes
- If you want to use RAM more than 64GB to increase Elasticsearch performence, it is recommended to use multiple nodes for Elasticsearch cluster instead in different machines
- For parsing, Celery generate workers based on CPU cores (worker per core), each core parse one machine at a time and when the machine finished, the other queued machines will start parsing, if you have large number of machines to process in the same time you have to increase the cores number
Installation
Run the following commands to clone the Kuiper repo via git.
$ git clone https://github.com/DFIRKuiper/Kuiper.git
Change your current directory location to the new Kuiper directory, and run the kuiper_install.sh bash script as root.
$ cd Kuiper/
$ sudo ./kuiper_install.sh -install
The kuiper_install.sh bash script will install all Kuiper dependencies such as (python, pip, redis, elasticsearch, mongodb and many others used by Kuiper default parsers).
If you want to change the default configuration of Kuiper, please visit the page Configuration
Use the following bash file to launch Kuiper.
$ ./kuiper_install.sh -run
If everything runs correctly now you should be able to use Kuiper through the link (http://[kuiper-ip]:[kuiper-port]/).
Happy hunting :).
Issues Tracking and Contribution
We are happy to receive any issues, contribution, and ideas.
we appreciate sharing any parsers you develop, please send a pull request to be able to add it to the parsers list.
Licenses
- Each parser has its own license, all parsers placed in the following folder
parsers/. - All files in this project under GPL-3.0 license, unless mentioned otherwise.