

Javascript Scanner for Recon, Vulnerabilities, and Secrets
Description
A simple yet effective tool to find using custom and predefined regex for recon, vulnerabilites and secrets. It scans concurrently and effectively on all urls for secrets and vulnerabilites. Scan for regexes even on non-javascript endpoint and output from other tools can be easily fed to it.
Features
- Fast and parallel scanning of all any endpoints for javascript using complex predefined regexes.
- Ability to define custom regex both case sensitive and case insensitive.
- Regex for DOM XSS sinks, sources, web services, hidden parameters, endpoints etc are already there
- Its built with faster_than_requests, ~40x faster than requests.
- Shannon entropy to catches whats missed by regex (may cause lengthy output and thus disabled by default)
Usage
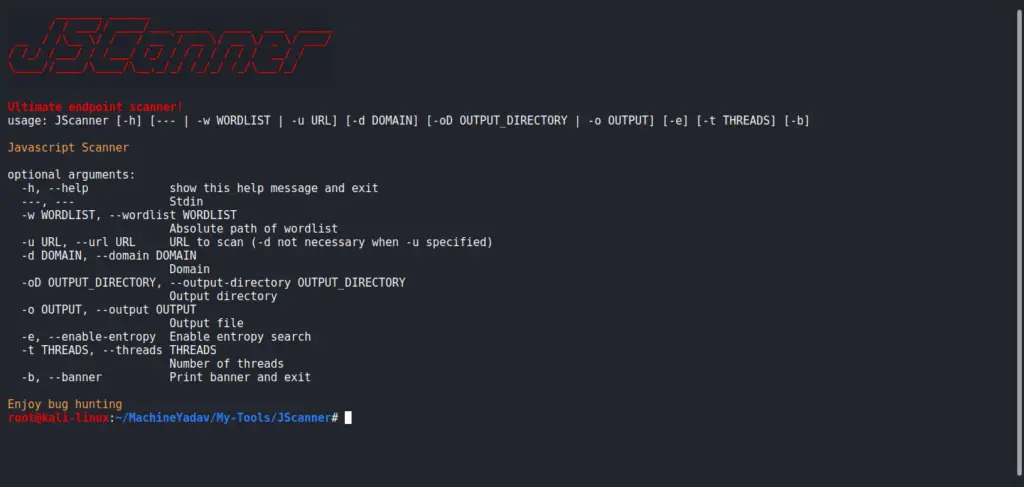
usage: JScanner [-h] [--- | -w WORDLIST] [-d DOMAIN]
[-oD OUTPUT_DIRECTORY | -o OUTPUT] [-t THREADS] [-b]
Javascript Scanner
optional arguments:
-h, --help show this help message and exit
---, --- Stdin
-w WORDLIST, --wordlist WORDLIST
Absolute path of wordlist
-d DOMAIN, --domain DOMAIN
Domain name
-oD OUTPUT_DIRECTORY, --output-directory OUTPUT_DIRECTORY
Output directory
-o OUTPUT, --output OUTPUT
Output file
-t THREADS, --threads THREADS
Number of threads
-b, --banner Print banner and exit
Enjoy bug hunting
Example
- Scan a single URL/Domain/Subdomain
JScanner -d google.com or JScanner -u https://google.com/closurelibrary.js
- Scan from URLs
JScanner -w hakrawler.txt -oD pwd -t 10 -d domain.com
- Scan from stdin (subdomains) with entropy check
assetfinder google.com | JScanner --- -o results.txt -e
- Scan from stdin (hakrawler, gau)
echo "uber.com" | tee >(hakrawler | JScanner --- -o hakrawler.txt -t 10) >(gau | JScanner --- -o gau.txt -t 10)
Caveats
- Repeated same type of webpage may cause repetition of data
- Even same page may caused repetition of data which sort -u fixes, however it is going to be fixed in further version
- Output from program as well as file output should be improved
Note
Download releases rather than git clone because developmental version may contain bugs. Releases are rather stable version! Also repetition needs to decreased in output.