
Grawler – tool written in PHP that automates the task of using google dorks
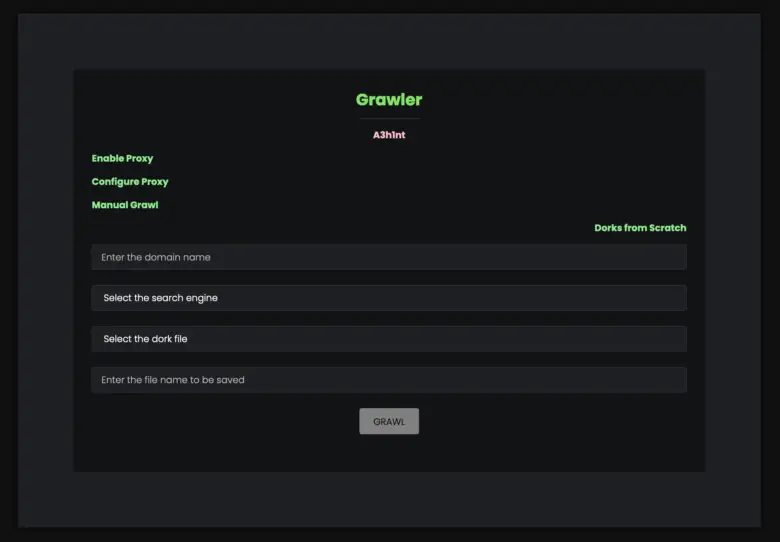
Grawler is a tool written in PHP which comes with a web interface that automates the task of using google dorks, scrapes the results, and stores them in a file.
General info
Grawler aims to automate the task of using google dorks with a web interface, the main idea is to provide a simple yet powerful tool that can be used by anyone, Grawler comes pre-loaded with the following features.
More: https://github.com/A3h1nt/Grawler
Features
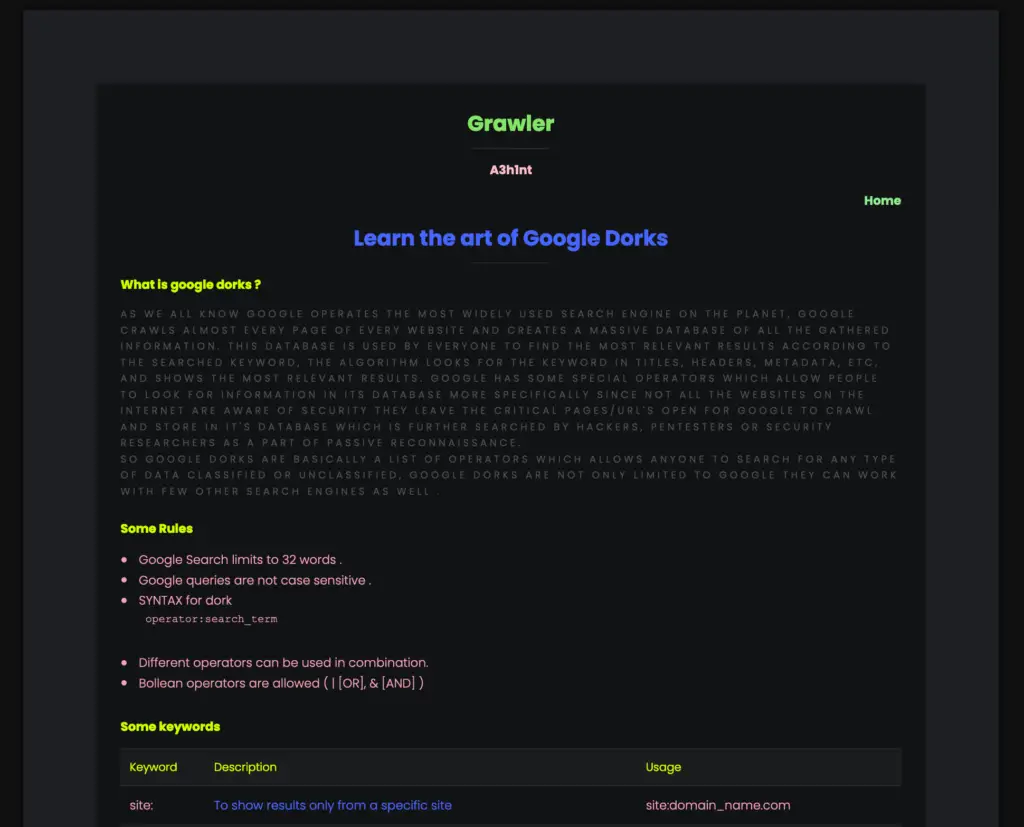
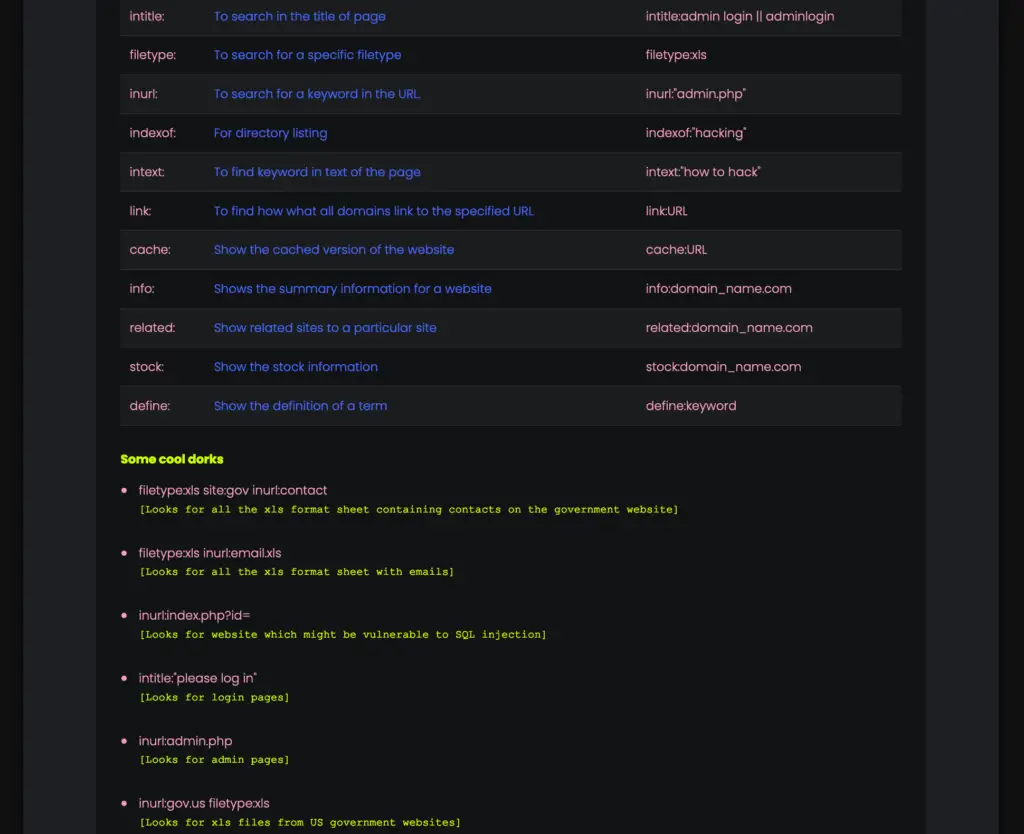
- Supports multiple search engines (Google, Yahoo, Bing)
- Comes with files containing dorks which are categorized in three categories as of now.
- Filetypes
- Login Pages
- SQL Injections
- My_dorks (This file is intentionally left blank for users to add their own list of dorks)
- Comes with its own guide to learn the art of google dorks.
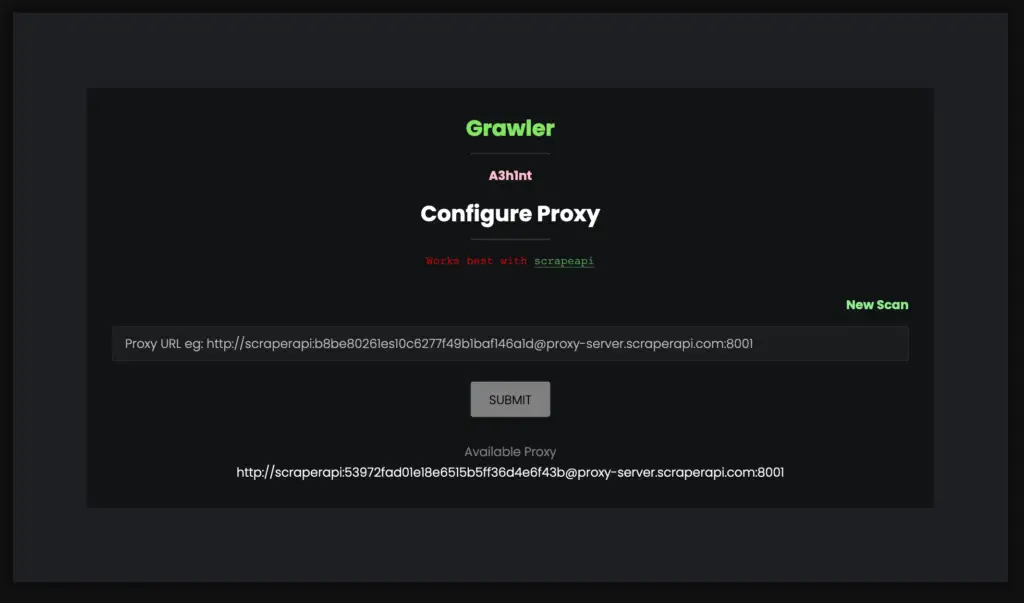
Built-in feature to use proxy (just in case google blocks you)
- aves all the scraped URL’s in a single file (name needs to be specified in the input field with extension .txt).
- Grawler can run in four different modes
- Automatic mode: Where the Grawler uses dorks present in a file and stores the result.
- Automatic mode with proxy enabled
- Manual mode: This mode is for users who only want to test a single dork against a domain.
- Manual mode with proxy enabled
Setup
- Download the ZIP file
- Download XAMPP server
- Move the folder to htdocs folder in XAMPP
- Navigate to http:// localhost /grawler
Demo
- How to run Grawler?
- There are several ways to use proxy , i have personally used Scrapeapi because they give free API calls without any credit card information or anything, and you can even get more API calls for free.
- How to setup proxy in Grawler?
- How to run Grawler in manual mode?
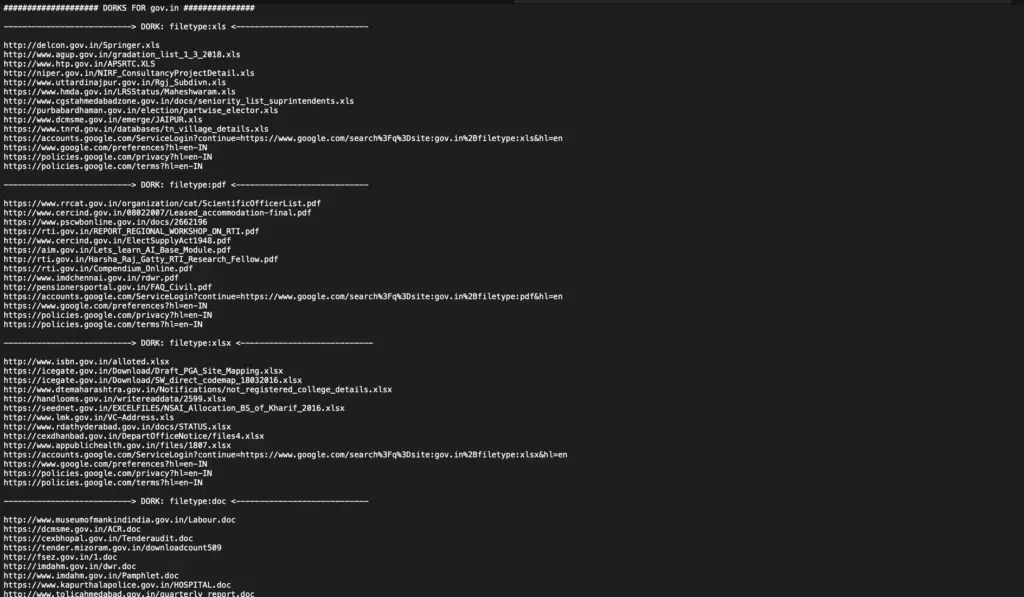
Sample Result
Captcha Issue
Sometimes google captcha can be an issue, because google rightfully detects the bot and tries to block it, there are ways that I’ve already tried to avoid captcha like :
- Using different user-agent headers and IP in a round-robin algorithm.
- It works but it gives a lot of garbage URLs that are not of any use and in addition to that it’s also slow, so I removed that feature.
- Using free proxy servers
- Free proxy servers are too slow and they often get blocked due to the fact that a lot of people use these free proxy servers for scraping.
- Sleep function
- This works up to some extent so I have incorporated it in the code.
- Tor Network
- Nope, doesn’t work every time I tried it, a beautiful captcha was presented, so I removed this functionality too.
Solution
- The best solution that I have found is to sign up for a proxy service and use it, it gives good results with less garbage URL’s but it can be slow sometimes.
- Use a VPN.
Contribute
- Report Bugs
- Add new features and functionalities
- Add more effective google dorks (which actually works)
- Workaround the captcha issue
- Create a docker image (basically, work on portability and usability)
- Suggestions
Contact Me
You can contact me here A3h1nt regarding anything.
