

DevOps methodology & roadmap for a devops developer in 2019. Interesting books to learn new technologies.
1. DevOps
1.1. What is DevOps?
DevOps is a software development methodology that combines software development (Dev) with information technology operations (Ops) participating together in the entire service lifecycle, from design through the development process to production support.
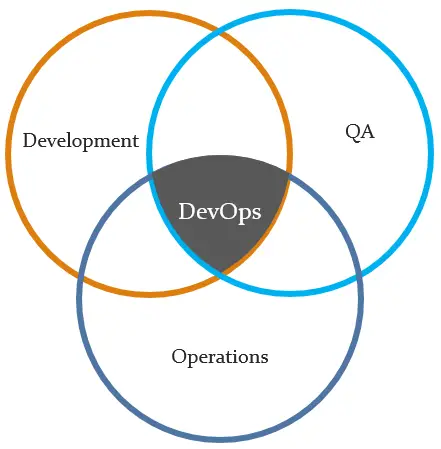
1.2. The goals of DevOps
- Fast Development Methodologies
- Fast Quality Assurance Methodologies
- Fast Deployment Methodologies
- Faster time to market
- Iteration & Continuous Feedback (strong and continuous communication between stakeholders – the end users and customers, product owners, development, quality assurance, and production engineers)
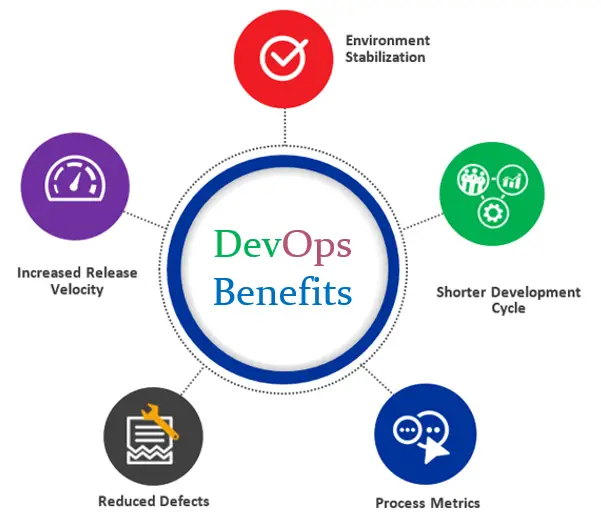
1.3. The benefits of DevOps
- Environment StabilizationEnforces consistency, increase up-time
- Shorter Development CycleManage requirements and code-repository
- Increased Release VelocityContinuous build, push-button deployments
- Reduced DefectsRegiment processes, automated testing
- Process MetricsTrack both time at each stage, and the errors and exceptions
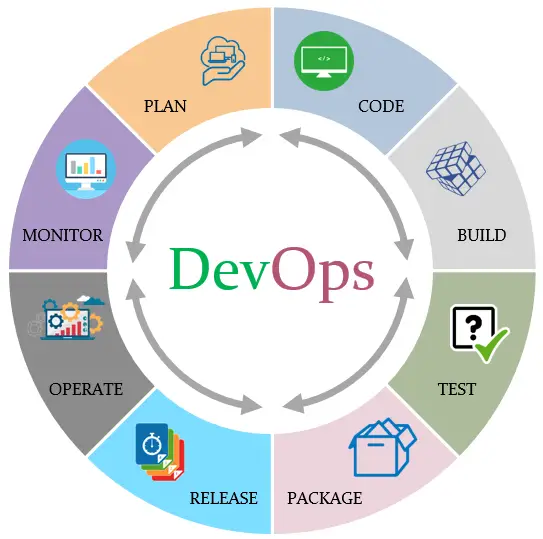
1.4. The steps of DevOps
- Plan: task management, schedules
- Code: code development and code review, source code management tools, code merging
- Build: continuous integration tools, version control tools, build status
- Test: continuous testing tools that provide feedback on business risks, determine performance
- Package: artifact repository, application pre-deployment staging
- Release: change management, release approvals, release automation
- Operate: infrastructure installation, infrastructure changes (scalability), infrastructure configuration and management, infrastructure as code tools, capacity planning, capacity & resource management, security check, service deployment, high availability (HA), data recovery, log/backup management, database management
- Monitor: service performance monitoring, log monitoring, end user experience, incident management
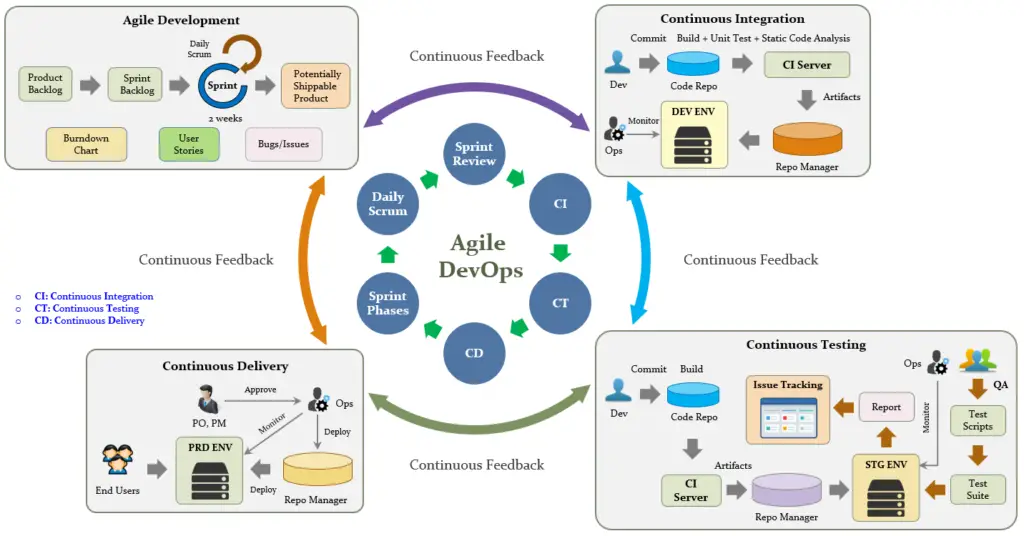
1.5. Agile DevOps Process
2. DevOps Technologies
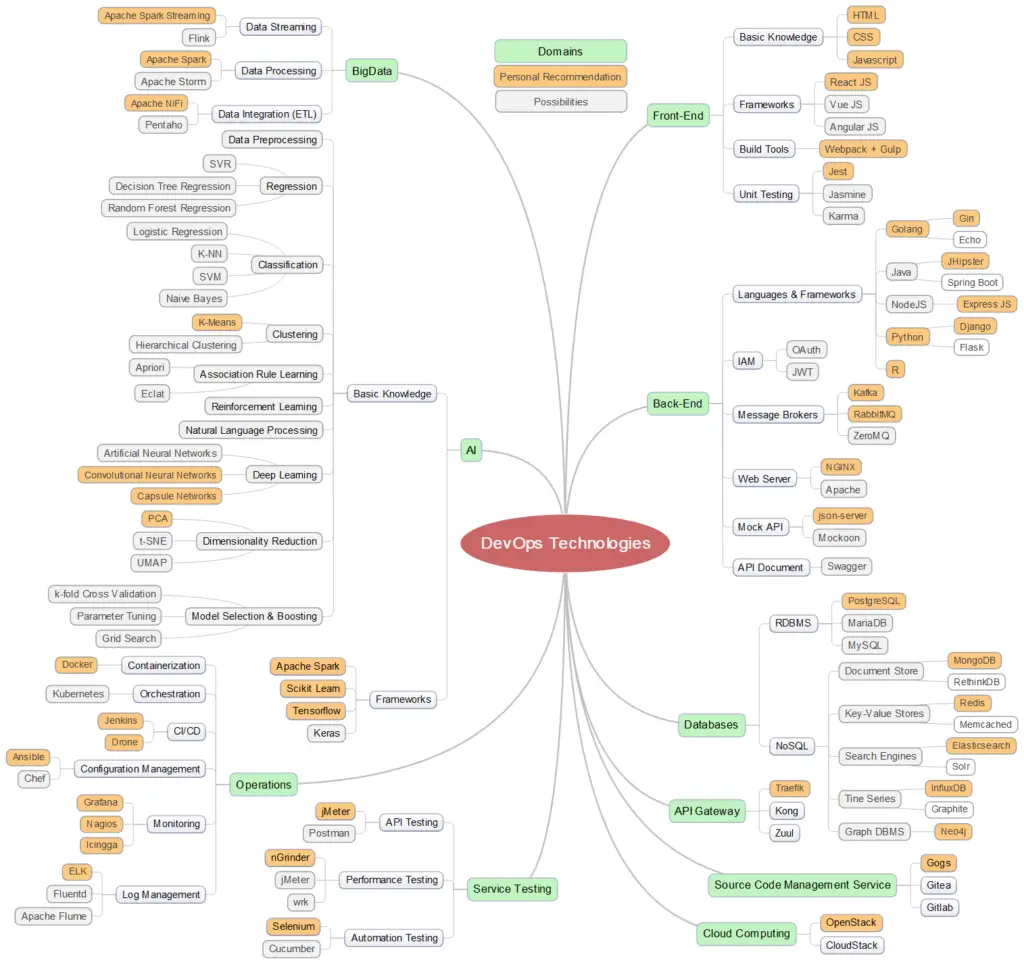
Roadmap for a DevOps developer
- Step 1: Learn a language
- Begin with HTML & CSS
- Learn basics of the JavaScript
- Understand TypeScript
- Step 2: Learn about source code management (recommend using Git)Reference: https://github.com/k88hudson/git-flight-rules
- Step 3: Practice what you have learnt
- Step 4: Learn Package Manager
- Step 5: Learn about Unit Testing
- Step 6: Learn about databases (RDBMS & NoSQL)
- Step 7: Learn frameworks
- Step 8: Learn how to implement caching
- Redis
- Memcached
- Step 9: Creating RESTful APIs
- Step 10: Learn about different Authentication/Authorization methods
- Step 11: Understand Message Brokers
- NSQ
- Kafka
- RabbitMQ
- ZeroMQ
- Step 12: Learn how to use Docker
- Step 13: Knowledge of Web Servers
- Step 14: Learn how to test service
- Test API
- Test Performance
- Test Security
- Test Automation
- Step 15: Learn different protocols
- TCP/UDP
- Web Socket
- AMQP
- MQTT
- Protocol Buffers
- gRPC
- Step 16: Learn Microservice, Event Driven, Lambda architectures
- Step 17: Learn Big Data technologies/tools
- Step 18: Learn algorithmsReference: https://github.com/TheAlgorithms/Python
- Step 19: Learn AI technologies
- Step 20: Learn configuration/deployment services
- Step 21: Learn how to monitor services
- Step 22: Use open source tools
- Mock REST APIs: https://github.com/typicode/json-server
- UML Designer: https://www.modelio.org
- Planning: https://wiki.gnome.org/Apps/Planner
- MindMap: MindMaple Lite
- UI Wireframe: Pencil (https://pencil.evolus.vn), Balsamiq
- SSH clients for Windows: SuperPuTTY
- Step 23: Keep exploring
3. Big Data
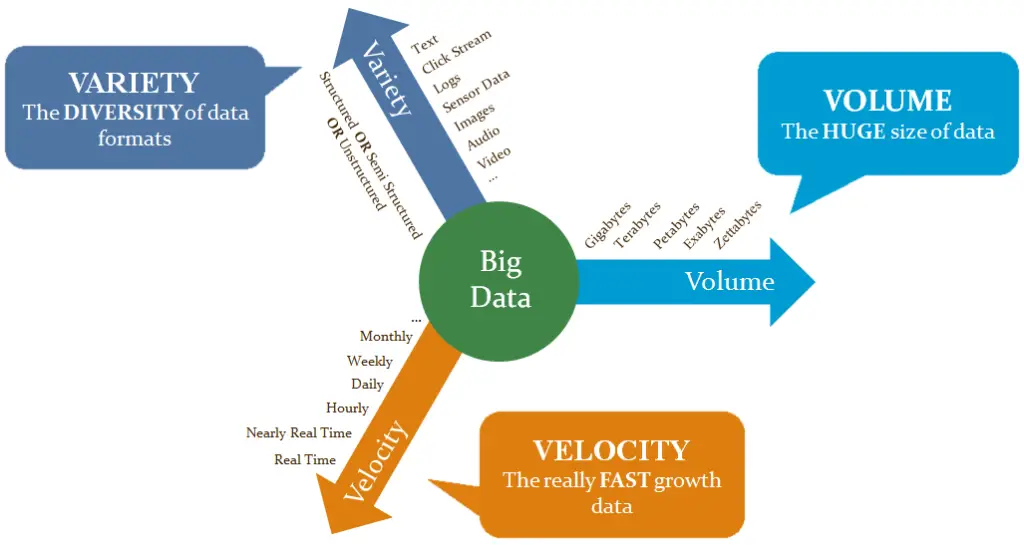
3.1. What is Big Data?
A collection of LARGE Datasets, so it can NOT be Processed by traditional methods…

[Source]: https://topics.amcham.com.tw/wp-content/uploads/2016/03/BigData_2267x1146_white.png
3.2. Characteristics of Big Data
3.3. Big Data Use Cases
- Recommendation System
- Clickstream Analysis
- Real-time Analytics
- Sentiment Analysis
- Clustering Analysis
- Search
- Customer Segmentation
- Fraud Detection/Prevention
- Internet of Things
- Image Classification
- Anomaly Detection
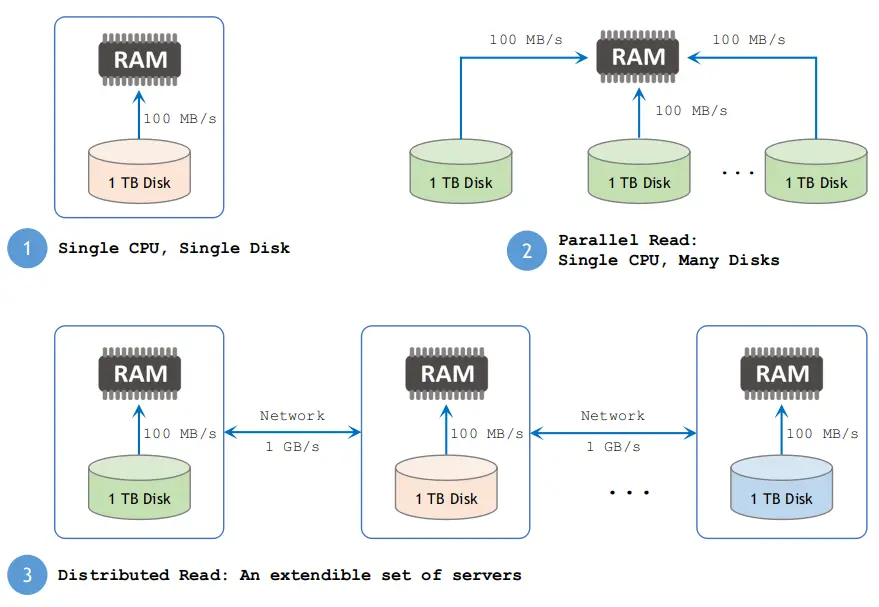
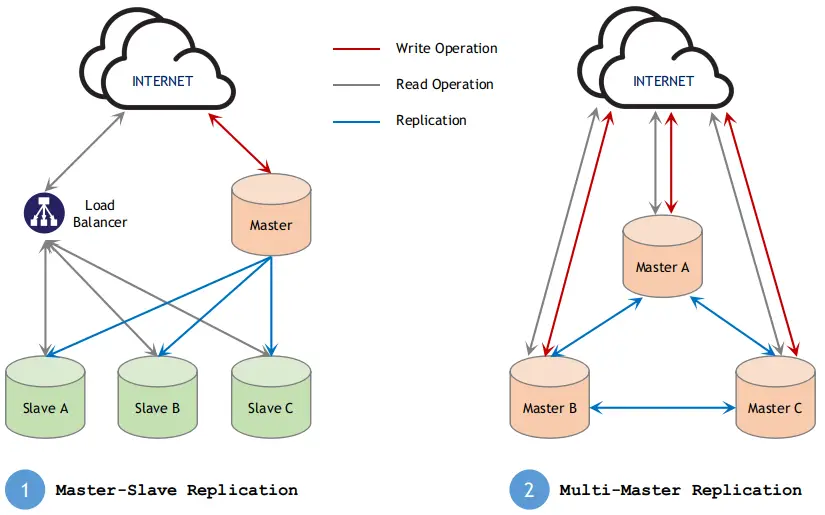
3.4. Big Data Solutions
- Distributed File System
- Distributed Database
- Distributed Computation
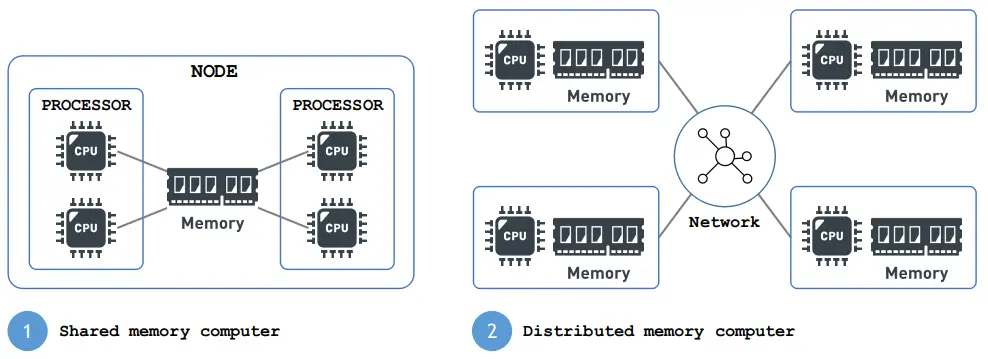
3.5. How Does Big Data Analysis Work?
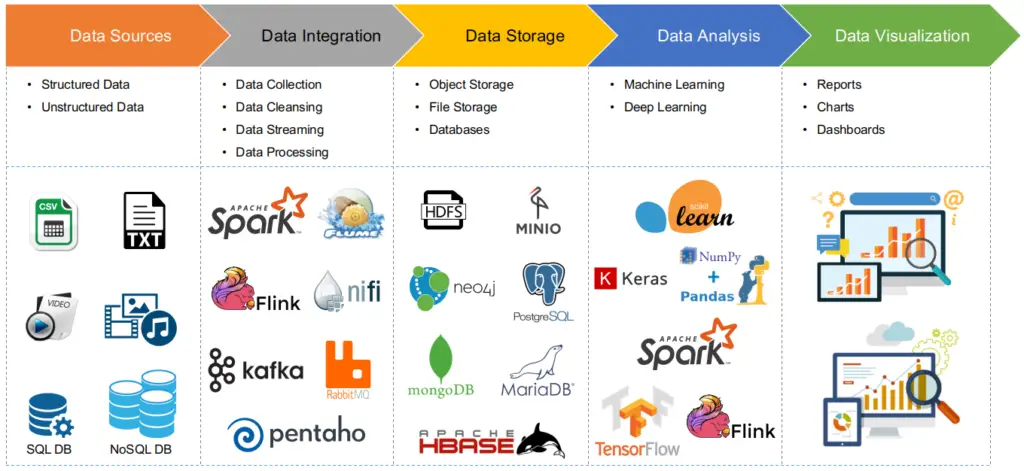
3.6. Why Messing?
- Data usually flows from one application to another. It is produced by one application and used by one or more other applications.
- Generally, the application generating or sending data is referred to as a producer, and the one receiving data is called a consumer.
- A simple way to send data from one application to another is to connect them to each other directly. However, tight coupling between producers and consumers requires them to be run at the same time or to implement a complex buffering mechanism. Therefore, direct connections between producers and consumers does not scale.
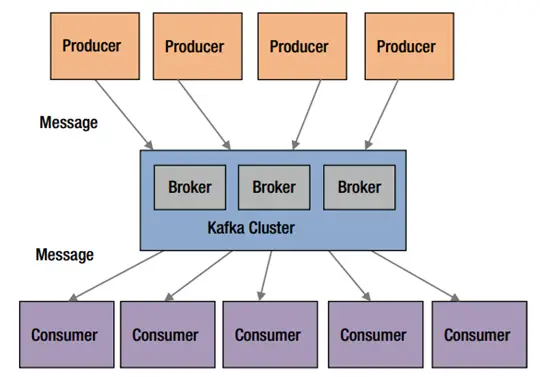
[Source]: Apache Kafka
A flexible and scalable solution is to use a message broker or messaging system. Instead of applications connecting directly to each other, they connect to a message broker or a messaging system. This architecture makes it easy to add producers or consumers to a data pipeline.
3.7. Batch Processing vs Stream Processing
- Batch Processing
In batch processing, newly arriving data elements are collected into a group. The whole group is then processed at a future time (as a batch, hence the term “batch processing”). Exactly when each group is processed can be determined in a number of ways–for example, it can be based on a scheduled time interval (e.g. every five minutes, process whatever new data has been collected) or on some triggered condition (e.g. process the group as soon as it contains five data elements or as soon as it has more than 1MB of data).
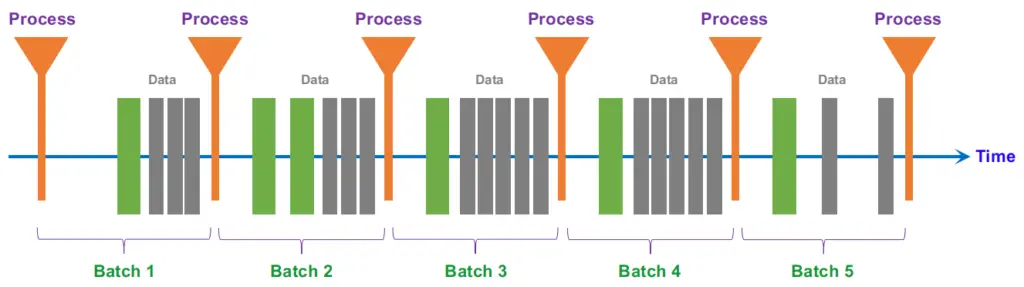
- Micro-Batch is frequently used to describe scenarios where batches are small and/or processed at small intervals. Even though processing may happen as often as once every few minutes, data is still processed a batch at a time.
- Stream Processing
In stream processing, each new piece of data is processed when it arrives. Unlike batch processing, there is no waiting until the next batch processing interval and data is processed as individual pieces rather than being processed a batch at a time.

Use cases:
- Algorithmic Trading, Stock Market Surveillance
- Monitoring a production line
- Intrusion, Surveillance and Fraud Detection ( e.g. Uber)
- Predictive Maintenance, (e.g. Machine Learning Techniques for Predictive Maintenance)
Batch Processing vs Streaming Processing
| Batch Processing | Stream Processing | |
|---|---|---|
| Data Scope | Queries or processing over all or most of the data in the dataset | Queries or processing over data within a rolling time window, or on just the most recent data record |
| Data Size | Large batches of data | Individual records or micro batches consisting of a few records |
| Performance | Latencies in minutes to hours | Requires latency in the order of seconds or milliseconds |
| Analyses | Complex analytics | Simple response functions, aggregates, and rolling metrics |
For more details please have a look at my other repo: https://github.com/raycad/stream-processing
4. Machine Learning
4.1. What is Machine Learning?
- Machine learning is creating and using models that are learned from data.
- Machine learning referred to as predictive modeling or data mining.Examples:
- Spam prediction
- Fraudulent credit card transaction prediction
- A product or advertisement recommendation engine
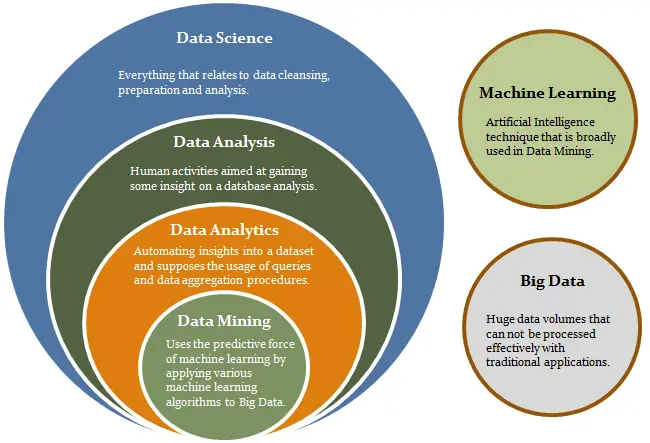
Data Science Fields
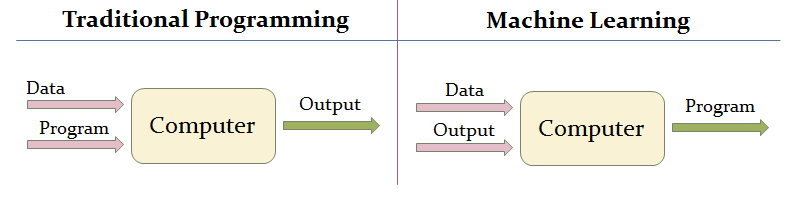
4.2. Traditional Programming vs Machine Learning
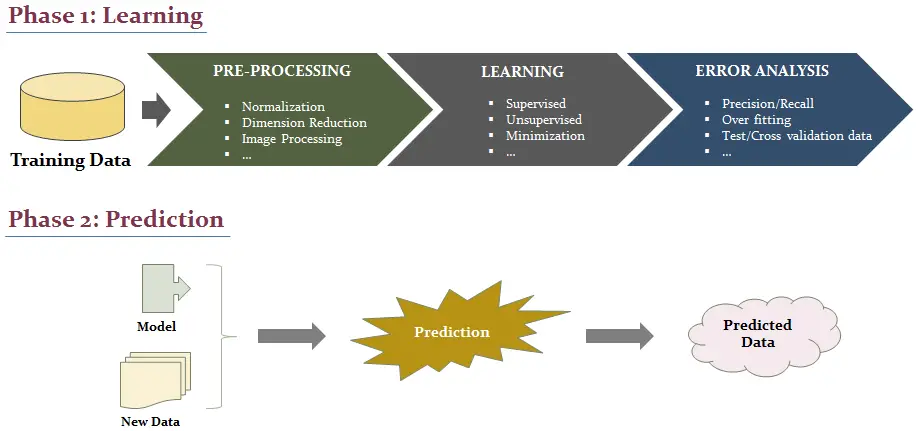
4.3. Machine Learning: Process
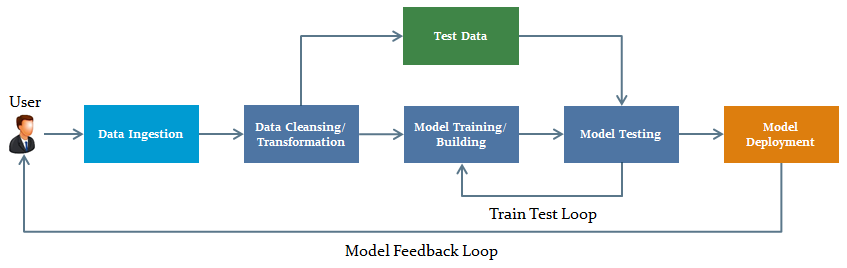
- Model Feedback Loop
- Deep Learning Model Build/Deployment
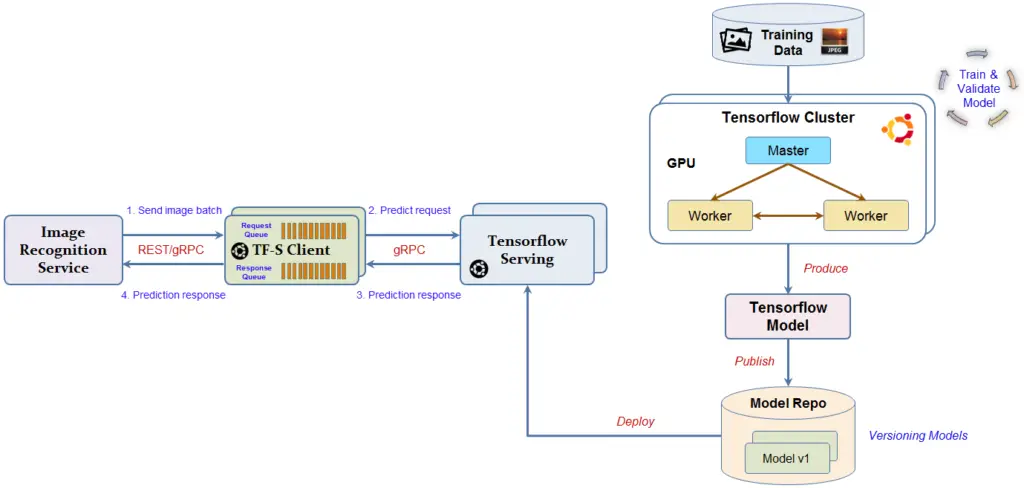
5. Books Recommendation
- Best Seller in Computer Neural Networks on Amazon 2018: Hands-On Machine Learning with Scikit-Learn and TensorFlow https://github.com/raycad/devops-roadmap/blob/master/books/ai/ml/hands_on_machine_learning_with_scikit_learn_and_tensorflow.pdf
- System Design Primer: https://github.com/raycad/devops-roadmap/blob/master/books/software-architecture/system_design_primer.pdf
- Programming Collective Intelligence: https://github.com/raycad/devops-roadmap/blob/master/books/ai/ml/oreilly_programming_collective_intelligence_aug_2007.pdf
- Azure Cloud Architecture: https://github.com/raycad/devops-roadmap/blob/master/books/software-architecture/azure_cloud_architecture.pdf
6. References
https://github.com/raycad/stream-processing
https://codeburst.io/the-2018-web-developer-roadmap-826b1b806e8d
