

Monitoring possible threats of your company on Internet is an impossible task to be achieved manually. Hence many threats of the company goes unnoticed until it becomes viral in public. Thus causing monetary/reputation damage. This is where RTTM comes into action. RTTM (Real Time Threat Monitoring Tool) is a tool developed to scrap all pasties,github,reddit..etc in real time to identify occurrence of search terms configured. Upon match an email will be triggered. Thus allowing company to react in case of leakage of code, any hacks tweeted..etc.. and harden themselves against an attack before it goes viral.
Over the past 2 years the tool has evolved from simple search. Artificial intelligence has been implemented to perform better search based on context. If regex is needed even that is supported. Thus behaviour is close to human and reduces false positives.
The best part of tool is that alert will be sent to email in less that 60 seconds from the time threat has made it to interent. Thus allowing response in real time to happen..
The same tool in malicious user hands can be used offensively to get update on any latest hacks, code leakage etc..
List of sites which will be monitored are:
- Non-Pastie Sites
- Github
- Pastie Sites
- Pastebin.com
- Codepad.org
- Dumpz.org
- Snipplr.com
- Paste.org.ru
- Gist.github.com
- Pastebin.ca
- Kpaste.net
- Slexy.org
- Ideone.com
- Pastebin.fr
Architecture:
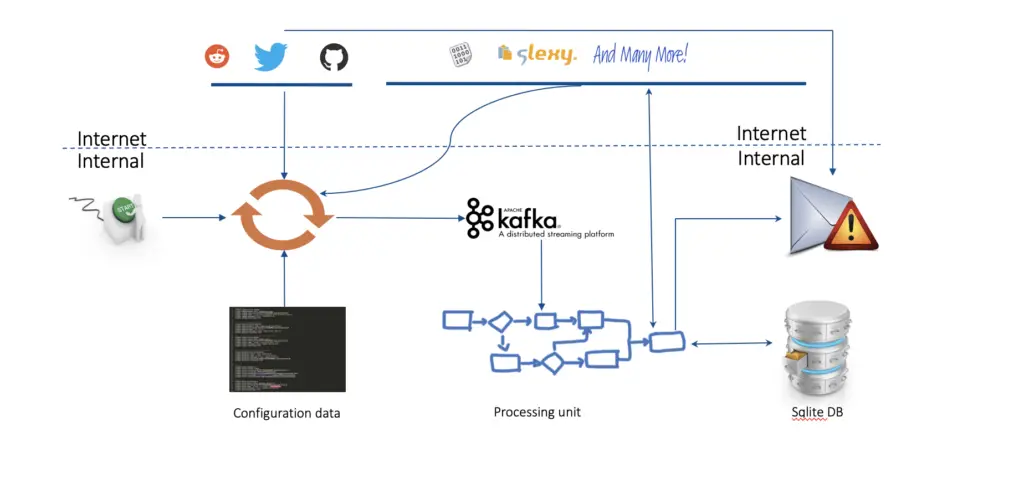
How it works?
Once the tool is started , engine gets kicked off and it runs forever. The main input for this engine is the configuration file. Based on the configuration file data, engine goes ahead and probes twitter/github/reddit for matches configured in configuration file. Upon a match is found, the link of twitter/github/reddit pushed to sqlite DB and an email alert is triggered.
In case of pastie sites the logic is different. The reason being they do not support search nor streaming api’s. Hence any new pastie made by any user, the link is fetched and pushed to kafka. From kafka any new link added is picked up and searched for matches configured in configuration file. Upon a match is found, the link of pastie site is pushed to sqlite DB and an email alert is triggered.
Over the past 2 years the tool has evolved from simple search. Artificial intelligence has been implemented to perform better search based on context. If regex is needed even that is supported. Thus behaviour is close to human and reduces false positives.
Configuration
Before using this tool is is neccessary to understand the properties file present in scrapper_config directory.
consumer.properties
Holds all the necessary config data needed for consumer of Kafka (Refer apache Kafka guide for more information). The values present here are default options and does nto require any changes
producer.properties
Holds all the necessary config data needed for Producer (Refer apache Kafka guide for more information).The values present here are default options and does nto require any changes
email.properties
Holds all the configuration data to send email.
scanner-configuration.properties
This is the core configuration file. Update all the config for enabling search on twitter/github(To get tokens and key refer respective sites).
For pastie sites and reddit there is no need for any changes in config.
Note:However in all cases make sure to change “searchterms” to values of our choice to search. If there are multiple search terms then add them seperate by comma like the example data provided in config file.
Understanding more about scanner-configuration.properties file.
For any pastie site configuration is as below:
Note: leave the pastie sites configuration as is and just change the search terms as requried by the organization. This will do good.
- scrapper.(pastie name).profile=(Pastie profile name)
- scrapper.(pastie name).homeurl=(URL from where pastie ids a extracted)
- scrapper.(pastie name).regex=(Regex to fetch pastie ids)
- scrapper.(pastie name).downloadurl= (URL to get information about each apstie)
- scrapper.(pastie name).searchterms=(Mention terms to be searched seperated by comma)
- scrapper.(pastie name).timetosleep=(Time for which pastie thread will sleep before fetching pastie ids again)
For github search configuration is as below:
- scrapper.github.profile=Github
- scrapper.github.baseurl=https://api.github.com/search/code?q={searchTerm}&sort=indexed&order=asc
- scrapper.github.access_token=(Get your own github access token)
- scrapper.github.searchterms=(Mention terms to be searched seperated by comma)
- scrapper.github.timetosleep=(Time for which github thred should sleep before searching again)
For reditt search configuration is as below: * scrapper.reddit.profile=Reddit
- scrapper.reddit.baseurl=https://www.reddit.com/search.json?q={searchterm}
- scrapper.reddit.searchterms=(Mention terms to be searched seperated by comma)
- scrapper.reddit.timetosleep=(Time for which github thred should sleep before searching again)
For Twitter search configuration is as below: * scrapper.twitter.apikey=test
- scrapper.twitter.profile=Twitter
- scrapper.twitter.searchterms=(Mention terms to be searched seperated by comma)
- scrapper.twitter.consumerKey=(Get your own consumer key)
- scrapper.twitter.consumerSecret=(Get your own consumerSecret)
- scrapper.twitter.accessToken=(Get your own accessToken)
- scrapper.twitter.accessTokenSecret=(Get your own accessTokenSecret)
API Key Setup
Twitter API Key:
- Go to https://dev.twitter.com/apps/new and log in, if necessary
- Enter your Application Name, Description and your website address. You can leave the callback URL empty.
- Accept the TOS, and solve the CAPTCHA.
- Submit the form by clicking the Create your Twitter Application
- Copy the consumer key (API key) and consumer secret from the screen into your application
Github API Key:
Refer link https://help.github.com/en/github/authenticating-to-github/creating-a-personal-access-token-for-the-command-line for detailed information.
Pastebin.com
In case of pastebin.com it is not neccessary to generate apiKey but you need to whitelist your IP. For thsi you have to pay and get your IP whitelisted.
Refer https://pastebin.com/doc_scraping_api for detailed information.
SetupGuide
Install via Docker
- Install docker in your system
- Download Dockerfile from https://github.com/NaveenRudra/RTTM
- Change directory to RTTM
- execute
docker build. - Run
docker exec -it <container id> /bin/bash - Now once in docker navigate to
/opt/RTTM/script - Run
intialize.shscript. This will boot mysql server and starts kafka. - Run
db_setup.shthis will created needed table. - Now from
/opt/RTTM run command java -jar scraptool/target/scraptool-1.0-SNAPSHOT-standalone.jar -t test -c /home/n0r00ij/RTS/scrapper_config/
Detailed Tool Documentation:
https://real-time-threat-monitoring.readthedocs.io/en/latest/
Developers:
Authors:
- Naveen Rudrappa
Contributors:
- Sunny Sharma
- Murali Segu