
Photon – Incredibly fast crawler designed for OSINT
Photon is a relatively fast crawler designed for automating OSINT (Open Source Intelligence) with a simple interface and tons of customization options. It’s written in Python. Photon essentially acts as a web crawler which is able to extract URLs with parameters, also able to fuzz them, secret AUTH keys, and a lot more.
Compatibility
Python Versions
Photon is fully compatible with Python versions 2.x – 3.x at present but will most likely end up deprecating python2.x support in the future as this project is under heavy development and may require features that aren’t available in python2.
Operating Systems
Photon has been tested on Linux (Arch, Debian, Ubuntu), Termux, Windows (7 & 10), Mac, and works as expected. Feel free to report any bugs you encounter.
Colors
Mac & Windows don’t support ANSI escape sequences so the output won’t be colored on Mac & Windows.
Dependencies
- TLD
- requests
The rest of the python libraries used by Photon are standard libraries that come preinstalled with a python interpreter.
Installing Photon
To install Photon all you have to do is clone the Github repository, install the dependencies, and run the script.
git clone https://github.com/s0md3v/photon.gitKey Features
Data Extraction
Photon can extract the following data while crawling:
- URLs (in-scope & out-of-scope)
- URLs with parameters (
example.com/gallery.php?id=2) - Intel (emails, social media accounts, amazon buckets etc.)
- Files (pdf, png, xml etc.)
- Secret keys (auth/API keys & hashes)
- JavaScript files & Endpoints present in them
- Strings matching custom regex pattern
- Subdomains & DNS related data
The extracted information is saved in an organized manner or can be exported as json.
Flexible
Control timeout, delay, add seeds, exclude URLs matching a regex pattern and other cool stuff. The extensive range of options provided by Photon lets you crawl the web exactly the way you want.
Genius
Photon’s smart thread management & refined logic gives you top-notch performance.
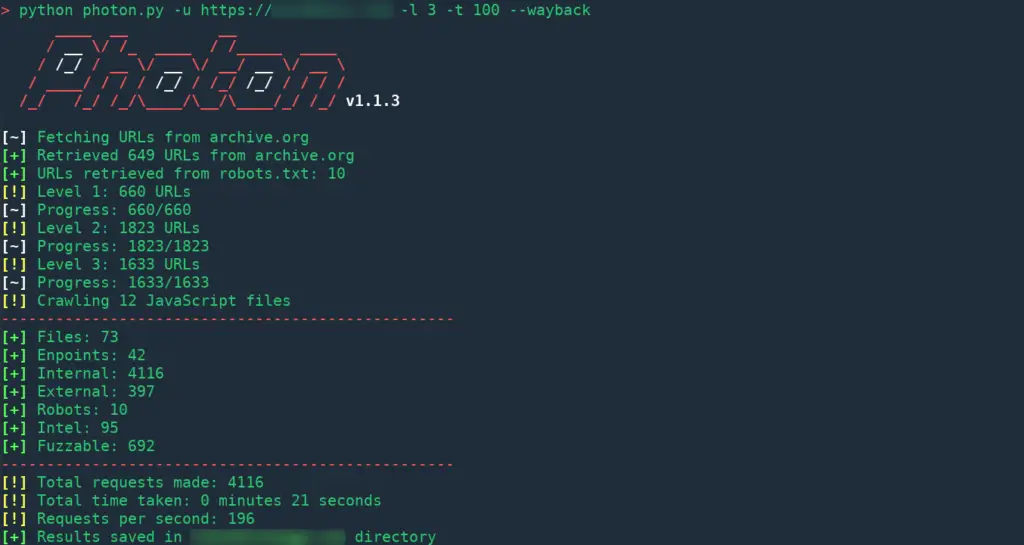
Still, crawling can be resource-intensive but Photon has some tricks up its sleeves. You can fetch URLs archived by archive.org to be used as seeds by using --wayback option.
Plugins
Docker
Photon can be launched using a lightweight Python-Alpine (103 MB) Docker image.
$ git clone https://github.com/s0md3v/Photon.git
$ cd Photon
$ docker build -t photon .
$ docker run -it --name photon photon:latest -u google.comTo view results, you can either head over to the local docker volume, which you can find by running docker inspect photonor by mounting the target loot folder:
$ docker run -it --name photon -v "$PWD:/Photon/google.com" photon:latest -u google.comFrequent & Seamless Updates
Photon is under heavy development and updates for fixing bugs. optimizing performance & new features are being rolled regularly.
If you would like to see features and issues that are being worked on, you can do that on the Development project board.
Updates can be installed & checked for with the --update option. Photon has seamless update capabilities which means you can update Photon without losing any of your saved data.
Usage
usage: photon.py [options]
-u --url root url
-l --level levels to crawl
-t --threads number of threads
-d --delay delay between requests
-c --cookie cookie
-r --regex regex pattern
-s --seeds additional seed urls
-e --export export formatted result
-o --output specify output directory
-v --verbose verbose output
--keys extract secret keys
--clone clone the website locally
--exclude exclude urls by regex
--stdout print a variable to stdout
--timeout http requests timeout
--ninja ninja mode
--update update photon
--headers supply http headers
--dns enumerate subdomains & dns data
--only-urls only extract urls
--wayback Use URLs from archive.org as seeds
--user-agent specify user-agent(s)Crawl a single website
Option: -u or --url
Crawl a single website.
python photon.py -u "http://example.com"
Clone the website locally
Option: --clone The crawled webpages can be saved locally for later use by using the --cloneswitch as follows
python photon.py -u "http://example.com" --clone
Depth of crawling
Option: -l or --level | Default: 2
Using this option user can set a recursion limit for crawling. For example, a depth of 2 means Photon will find all the URLs from the homepage and seeds (level 1) and then will crawl those levels as well (level 2).
python photon.py -u "http://example.com" -l 3
Number of threads
Option: -t or --threads | Default: 2
It is possible to make a concurrent request to the target and -t the option can be used to specify the number of concurrent requests to make. While threads can help to speed up crawling, they might also trigger security mechanisms. A high number of threads can also bring down small websites.
python photon.py -u "http://example.com" -t 10
The delay between each HTTP request
Option: -d or --delay | Default: 0
It is possible to specify the number of seconds to hold between each HTTP(S) request. The valid value is a int, for instance, 1 means a second.
python photon.py -u "http://example.com" -d 2
Timeout
Option: --timeout | Default: 5
It is possible to specify the number of seconds to wait before considering the HTTP(S) request timed out.
python photon.py -u "http://example.com --timeout=4
Cookies
Option: -c or --cookies | Default: no cookie header is sent
This option lets you add a Cookie header to each HTTP request made by Photon in non-ninja mode.
It can be used when certain parts of the target website require authentication based on Cookies.
python photon.py -u "http://example.com" -c "PHPSESSID=u5423d78fqbaju9a0qke25ca87"
Specify the output directory
Option: -o or --output | Default: domain name of target
Photon saves the results in a directory named after the domain name of the target but you can overwrite this behavior by using this option.
python photon.py -u "http://example.com" -o "mydir"
Verbose output
Option: -v or --verbose
In verbose mode, all the pages, keys, files, etc. will be printed as they are found.
python photon.py -u "http://example.com" -v
Exclude specific URLs
Option: --exclude
URLs matching the specified regex will not be crawled or showed in the results at all.
python photon.py -u "http://example.com" --exclude="/blog/20[17|18]"
Specify seed URL(s)
Option: -s or --seeds
You can add custom seed URL(s) with this option, separated by commas.
python photon.py -u "http://example.com" --seeds "http://example.com/blog/2018,http://example.com/portals.html"
Specify user-agent(s)
Option: --user-agent | Default: entries from user-agents.txt
You can use your own user agent(s) with this option, separated by commas.
python photon.py -u "http://example.com" --user-agent "curl/7.35.0,Wget/1.15 (linux-gnu)"
This option is only present to aid the user to use a specific user agent without modifying the default user-agents.txt file.
Custom regex pattern
Option: -r or --regex
It is possible to extract strings during crawling by specifying a regex pattern with this option.
python photon.py -u "http://example.com" --regex "\d{10}"
Export formatted result
Option: -e or --export
With -e the option you can specify an output format in which the data will be saved.
python photon.py -u "http://example.com" --export=json
Currently supported formats are:
- JSON
- CSV
Use URLs from archive.org as seeds
Option: --wayback
This option makes it possible to fetch archived URLs from archive.org and use them as seeds. Only the URLs crawled within the current year will be fetched to make sure they aren’t dead.
python photon.py -u "http://example.com" --wayback
Skip data extraction
Option: --only-urls
This option skips the extraction of data such as intel and js files. It should come in handy when your goal is to only crawl the target.
python photon.py -u "http://example.com" --only-urls
Update
Option: --update
If this option is enabled, photon will check for updates. If a newer version will available, Photon will download and merge the updates into the current directory without overwriting other files.
python photon.py --update
Extract secret keys
Option: --keys
This switch tells Photon to look for high entropy strings which can be some kind of auth or API keys or hashes.
python photon.py -u http://example.com --keys
Piping (Writing to stdout)
Option: --stdout
You can write a variety of choices to stdout for piping with other programs.
Following variables are supported:
files, intel, robots, custom, failed, internal, scripts, external, fuzzable, endpoints, keys
python photon.py -u http://example.com --stdout=custom | resolver.py
Ninja Mode
Option: --ninja
This option enables Ninja mode. In this mode, Photon uses the following websites to make requests on your behalf.TimeoutThis option enables Ninja mode. In this mode, Photon uses the following websites to make requests on your behalf.
Contrary to the name, it doesn’t stop you from making requests to the target.\
Dumping DNS data
Option: --dns
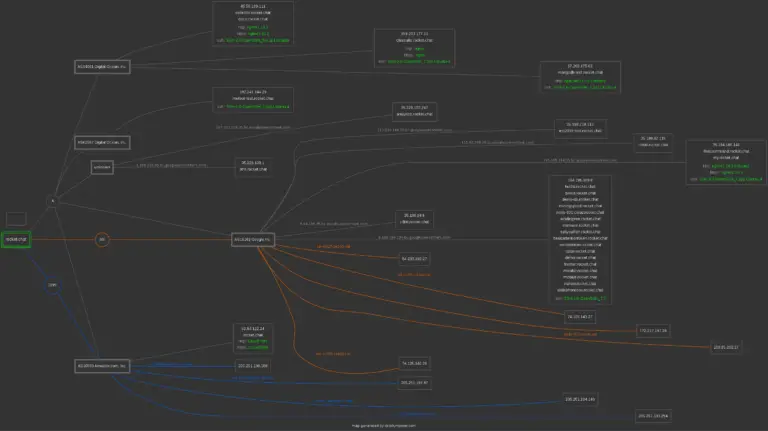
Saves subdomains in ‘subdomains.txt’ and also generates an image displaying the target domain’s DNS data.
python photon.py -u http://example.com --dns
Sample Output:
Contribution & License
You can contribute in the following ways:
- Report bugs
- Develop plugins
- Add more “APIs” for ninja mode
- Give suggestions to make it better
- Fix issues & submit a pull request
Please read the guidelines before submitting a pull request or issue.