


HDFS Distributed File copy
Hadoop provides HDFS Distributed File copy (distcp) tool for copying large amounts of HDFS files within or in between HDFS clusters.
It is implemented based on Mapreduce framework and thus it submits a map-only mapreduce job to parallelize the copy process. Usually this tool is useful for copying files between clusters from production to development environments.
It supports some advanced command options while copying files. Below are the list of command options it supports.
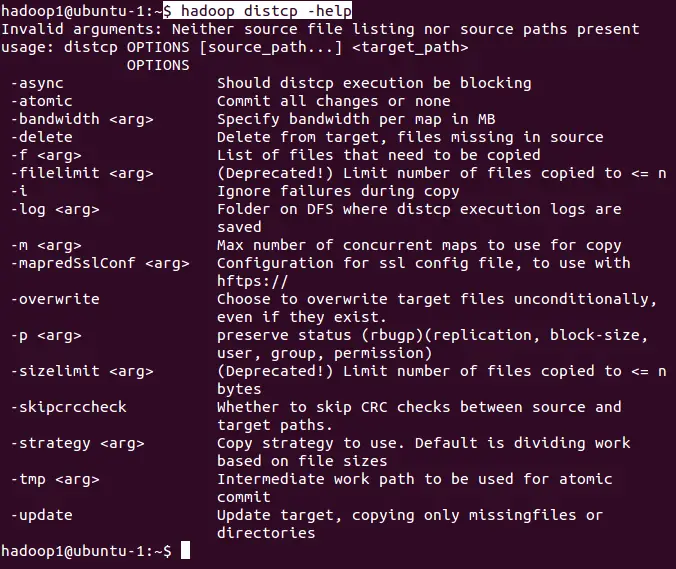
The basic syntax for using this command is
$ hadoop distcp hdfs://namenodeX/src hdfs://namenodeY/dest $ hadoop distcp hdfs://nameservice1/user/hive/warehouse/ap_us_stage.db/sales_market hdfs://nameservice2/user/aravind/sales_market
This command can be run from source machine/environment.
In this post, parallel copying within same cluster is described. then hdfs://namenode can be removed from the syntax.
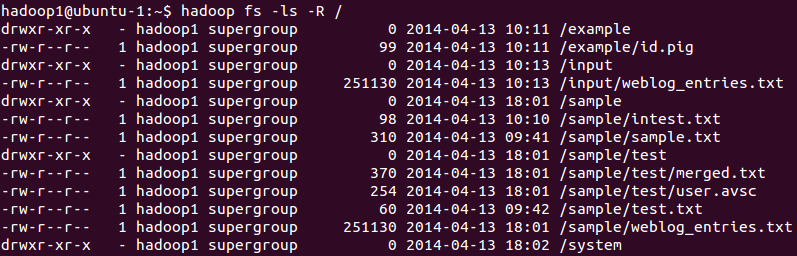
1. Below is the screen shot of source and destination directory structure before copying:
2. Triggering distcp command.
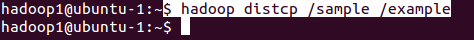
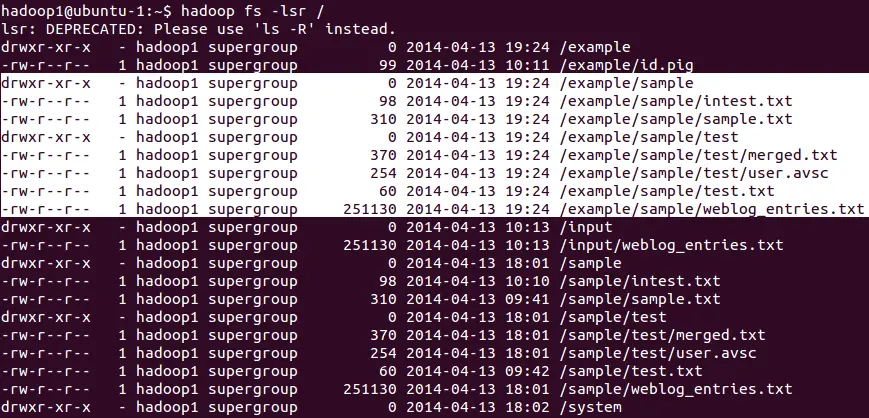
3. The entire source directory /sample will be copied into output directory resulting in directory structure of /example/sample.
Some of the frequently useful command options are listed below. All these are not mandatory but just optional.
i). -atomic: This option is used to either commit all changes at a time or no changes should be committed. This makes sure that no partial copying is allowed. Either all files are copied entirely or no file is copied.
ii). -overwrite: By default distcp will skip copying the files that already exist in the destination directory but these can be overwritten unconditionally with this option.
iii). -update: If we need to copy only missing files or changed files, this options is very helpful and minimizes the copy time by copying only missing files/updated files instead of all the source files.
iv). -m <arg> : This option lets user to specify the maximum number of mappers to be used.
v). -delete : Deletes the existing files in the destination directory but not in source directory.
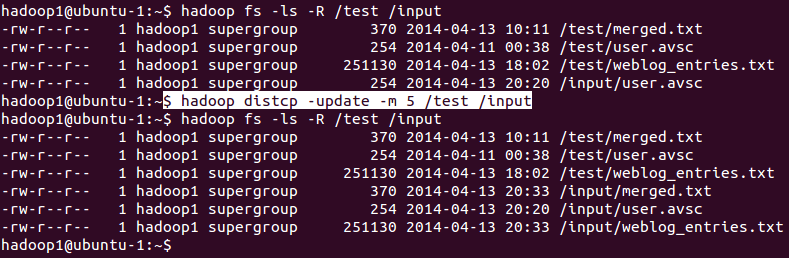
In the below example, we have copied only missing files from /test to /input directory using maximum of 5 mappers.
Directory structures before issuing distcp and after issue are also presented.
Advantages over hadoop fs -put command or hadoop fs -cp:
hadoop fs -put command or hadoop fs -cp command can be used to copy the files from local file system into hadoop cluster and from one hadoop cluster to another respectively but here the process is sequential, i.e. only one process will be run to copy file by file. But the advantage of using hadoop distcp command will give us the flexibility to specify the number of parallel tasks should be run in the background to copy files between clusters.
Thus by parallel processing, hadoop’s distcp is the better option to copy bulk data/ huge number of files from one machine to another (or cluster to cluster) than using fs -put or fs -cp commands.