

Top 20 Best Machine Learning Datasets for Practicing Applied ML
We all know that to build up a machine learning project, we need a dataset. Generally, these machine learning datasets are used for research purpose. A dataset is the collection of homogeneous data. Dataset is used to train and evaluate the machine learning model. It plays a vital role to build up an efficient and reliable system. If your dataset is noise-free and standard, then your system will give better accuracy. However, at present, we are enriched with numerous datasets. It can be business-related data, or it can be medical data and many more. However, the actual problem is to find out the relevant ones according to the system requirements.
20 Best Machine Learning Datasets
For developing a machine learning and data science project its important to gather relevant data and create a noise-free and feature enriched dataset. Below we are narrating the 20 best machine learning datasets such a way that you can download the dataset and can develop your machine learning project. After analyzing the web hours after hours, we have outlined this to boost up your machine learning knowledge.
1. ImageNet

ImageNet is one of the best datasets for machine learning. Generally, it can be used in computer vision research field. This project is an image dataset, which is consistent with the WordNet hierarchy. In WordNet, each concept is described using synset. Synset is multiple words or word phrases. In WordNet approximately 100,000+ synsets are available.
Features
- In each synset, ImageNet provides 1000 images.
- ImageNet only provides the URLs of images.
- It is very much beneficial for academic researchers because of its large-scale image database.
- You can also download image features.
2. Breast Cancer Wisconsin (Diagnostic) Data Set
Another mentionable machine learning dataset for classification problem is breast cancer diagnostic dataset. It’s a well-known dataset for breast cancer diagnosis system. This breast cancer diagnostic dataset is designed based on the digitized image of a fine needle aspirate of a breast mass. In this digitized image, the features of the cell nuclei are outlined.
Features
- There are three types of attributes available, i.e., ID, diagnosis, 30 real-valued input features.
- For each cell nucleus, ten real-valued features are calculated, i.e., radius, texture, perimeter, area, etc.
- There are two types of predicting filed, i.e., benign and malignant.
- In this database, there are 569 instances which include 357 benign and 212 malignant.
3. Twitter Sentiment Analysis Dataset
We all know that sentiment analysis is a popular application of natural language processing (NLP). Are you interested in building a model of sentiment analyzer? Then, this twitter sentiment analysis dataset is for you — also, its a task of text processing. Moreover, if you are a fresher/beginner in the machine learning world, then you may use this interesting machine learning dataset. It may help you to enhance your machine learning skill.
Features
- In this dataset, there are three types or tones of data, i.e., neutral, positive, and negative.
- The file format is CSV.
- There are train data (train.csv) and test data (test.csv) file in this dataset. You have to build the model using the train data. For evaluation, you have to use test data.
- Two data fields are available, i.e., ItemID (ID of tweet) and SentimentText (text of the tweet).
4. BBC News Datasets
One of the most renowned problems of text classification is news classification. So, to develop your news classifier, you need a standard dataset. This BBC news dataset is just worthy. There are five predefined classes. In business class, there are 510 documents, in entertainment class, 386 documents, in a politics class, 417 documents, in sport class, 511 documents, and in technology class, 401 documents.
Features
- If you want you can download only pre-processed dataset or raw text files of BBC news data according to the system demand.
- Includes 2225 documents from the BBC official news website.
- You may use 50% data as a training dataset and rest as test dataset or as your system requirement.
- To use this dataset, you must have to cite this paper.
5. MNIST Dataset
Do you want to work with handwritten digits? Then this MNIST dataset may help you to build your model. This Machine learning dataset is for image recognition. Its a well known and interesting machine learning dataset. The surprising fact of this dataset is that it offers both 60000 instances for training and 10000 for testing.
Features
- This dataset helps you to understand and learn how to use ML techniques and pattern recognition methods on real-world data.
- There are four types of files available, i.e., train-images-idx3-ubyte.gz, train-labels-idx1-ubyte.gz, t10k-images-idx3-ubyte.gz, and t10k-labels-idx1-ubyte.gz.
- The training set and testing set are disjoint from each other.
- Get binary images of handwritten digits using NIST’s Special Database 3 and Special Database 1.
6. Amazon Reviews Dataset
We all know natural language processing is about text data. In the web, there are an enormous unstructured data is here and there. So, to solve a real-world application, you need ML dataset. Also, this Amazon reviews dataset is one of them. It contains 35 million reviews from Amazon spanning 18 years (up to March 2013).
Features
- It consists of reviews from Amazon.
- Product and user information, ratings, and review are included.
- You have to cite this paper: J. McAuley and J. Leskovec. Hidden factors and hidden topics: understanding rating dimensions with review text. RecSys, 2013.
- In this dataset, duplicate data may be found.
7. Spam SMS Classifier Dataset
Among so many machine learning applications, spam classification or spam detection is interesting one. Also, it’s a well-known task for an academic project or machine learning research. However, if you are a beginner in this field, you can build or develop a spam classifier using this dataset. This SMS Spam dataset may be a set of SMS labeled messages that are collected for SMS Spam analysis.
Features
- This dataset contains 5,574 messages, which is written in English.
- Each line contains one message.
- Each line has two columns: one column contains the label (ham or spam), and the other one includes the raw text.
- The file format is CSV.
8. YouTube Dataset
Are you an expert in machine learning research area or want to do something with video classification? Then, this dataset for machine learning project might help you. Also, you might be glad to know that Google has shared a labeled dataset with 8M classified YouTube Videos and its’ IDs.
Features
- This dataset is a large-scaled label dataset with high-quality machine-generated annotations.
- Videos are sampled uniformly, and each video is associated with at least one entity from the target vocabulary.
- To filter the video labels, they use both automated and manual curation strategies.
- You can download the CSV file of their vocabulary.
9. The Chars74K Dataset
Character recognition is one of the classic classification problems of pattern recognition. Researches are working in this problem from the beginning of computer vision. This interesting machine learning dataset consists of 64 classes (0-9, A-Z, a-z), 7705 characters taken from natural images, 3410 hand-drawn characters, and 62992 synthesized characters from computer fonts.
Features
- Chars74k contains large labeled dataset.
- This dataset contains symbols in both English and Kannada.
- In Kannada, there are almost 657 additional classes.
10. Facial Image Dataset
Do you need a dataset for your machine learning research purpose? Then, here is good news for you. You can use this interesting machine learning dataset for your computer vision project. This dataset is standard and free to use. Moreover, it contains a variation of data like variation of background and scale, and variation of expressions. This standard dataset helps to evaluate a system precisely.
Features
- You get the data in four directories. Therefore, you can download anyone according to your system requirement and demand.
- For your convenience, the zipped versions of all the data in each directory are available.
- There are 395 individuals, and each has 20 images.
- The image resolution is 180 by 200 pixels and stored in 24 Bit RGB, and JPEG format.
11. Wine Quality Dataset
If you want to develop a simple but quite exciting machine learning project, then you can develop a system using this wine quality dataset. By using this dataset, you can build a machine which can predict wine quality. This dataset is formed based on wines physicochemical properties. To build an up to a wine prediction system, you must know the classification and regression approach. So, if you are a beginner, this is the best for your practice.
Features
- In this dataset, there are two types of variables, i.e., input and output variables. Input variables are fixed acidity, volatile acidity, citric acid, residual sugar, and so forth. The output variable is quality.
- There are 12 attributes, and the attribute characteristics are real.
- The number of instances is 4898.
- There are two datasets included. Moreover, these datasets correspond to red and white vinho Verde wine, which comes from the north of Portugal.
12. Iris Flowers Dataset

If you are a beginner and want to develop a simple project, then you can use this simple Iris Flowers Dataset. It is one of the best datasets of pattern recognition. This dataset is small, and no pre-processing is needed to apply in your machine learning project. The dataset of Iris flowers has numeric attributes, as an instance, sepal and petal length and width.
Features
- There are four attributes, i.e., sepal length in cm, sepal width in cm, petal length in cm, and petal width in cm.
- This dataset contains three classes, and each class has 50 instances. The classes are virginica, setosa, and versicolor.
- The dataset characteristics are multivariate.
- All of the attributes are real.
13. Labelme
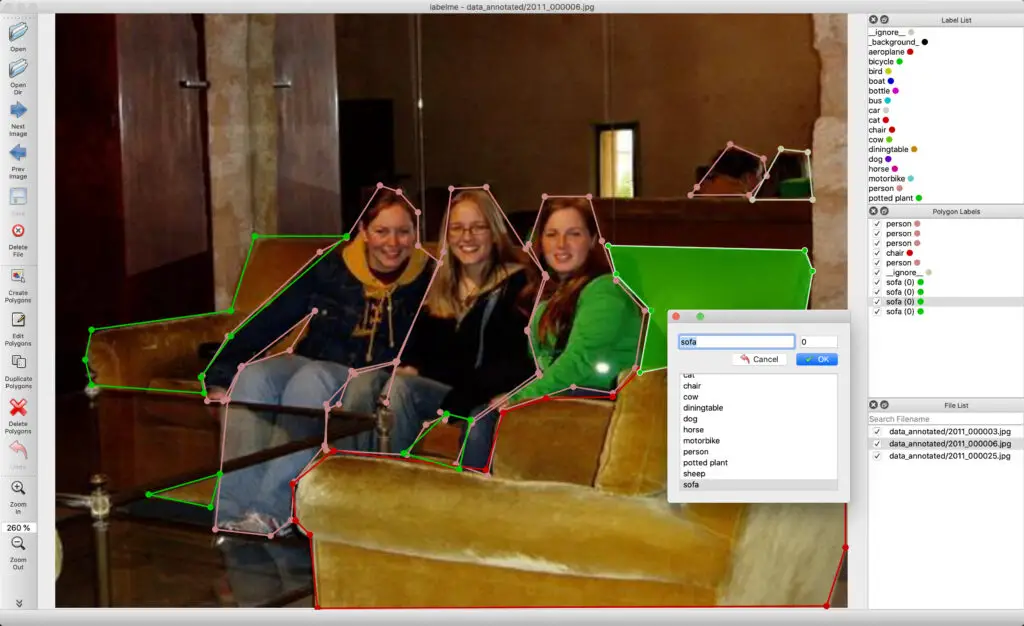
Image processing is one of the amazing is of machine learning. Recently, researchers and developers are working in this field tremendously. They always try to innovate new features by processing an image. If you are also interested in developing an image processing system, then you can use this Labelme dataset in your machine learning project. This dataset is a large volume dataset of annotated images.
Features
- There are two options to download this dataset.
- The first one is that you can download all the images using the LabelMe Matlab toolbox.
- And the second one is that you can access the online database with the LabelMe Matlab toolbox.
- LabelMe provides an online annotation tool for computer vision research.
14. HotpotQA
Do you want to work with natural language processing? We all know natural language processing covers a big range area in machine learning. So, if you’re going to develop a system based on natural language processing (NLP) concept, then you can build a system using this hotpotQA machine learning dataset. It is collected by a team of NLP researchers at Carnegie Mellon University, Stanford University, and Université de Montréal.
Features
- It’s a question answering dataset which contains multi-hop questions.
- You can use this dataset for your academic or research purpose.
- For details, you may read this paper.
- If you use this dataset, then you must have to cite their paper.
15. xView

If you are an expert in machine learning and you can handle a tricky problem or project, then I must suggest you use this dataset in your project or system. This dataset is one of the standard datasets for imaging problem. Moreover, it is one of the most extensive public datasets.
Features
- This dataset contains overhead imagery, and it has 60 classes.
- Images are tricky scenery around the world.
- 1M object instances are included.
- It’s a set of small, exceptional, fine-grained, and multi-type instances which are annotated using bounding box.
16. US Census Data (1990) Data Set
This standard, USCensus1990raw data set includes a sample of the Public Use Microdata Samples (PUMS) person records. The raw data set collected from the U.S. Department of Commerce Census Bureau website. Data extraction system is applied to collect the data. The dataset characteristic is multivariate. Also, the attribute characteristic is categorical.
Features
- 68 categorical attributes are included.
- You have to know the clustering algorithms.
- In this dataset, mapping is done to form new variables from the old variables.
- The data is available in .txt format.
17. Boston House Price Dataset
Do you want to practice regression algorithm? Then you can use this dataset in your machine learning problem. This dataset is collected from the area of Boston Mass.
Features
- The dataset contains 506 cases.
- There are 14 attributes in each case, i.e., CRIM, AGE, TAX, and so forth.
- The file format is CSV.
- You must know the regression algorithm.
18. Banknote Authentication Dataset
Another interesting machine learning dataset is the banknote authentication dataset. This dataset is about checking out the genuine and forged banknotes. In this dataset, data were taken from the images of genuine and forged banknote. Moreover, the images are 400 by 400 pixels. To extract the features from these images, a Wavelet transform tool was used.
Features
- There are five attributes, i.e., the variance of Wavelet Transformed image, skewness of Wavelet Transformed image, curtosis of Wavelet Transformed image, the entropy of image, and class.
- It’s a classification task.
- The number of instances is 1372.
- There is no missing value.
19. Pima Indians Diabetics Dataset
If you want to apply machine learning in healthcare, then you can use this Pima Indian Diabetics dataset in your healthcare system. We all know that diabetes is one of the most common dangerous diseases. You can use this dataset in your diabetes detection system. This dataset is from the National Institute of Diabetes and Digestive and Kidney Diseases. The objective of this dataset is to predict whether or not a patient has diabetes based on specific diagnostic measurement.
Features
- The file format of this dataset is CSV.
- All the patients of this dataset are female, and at least 21 years old.
- The dataset consists of several medical predictor variables, i.e., number of pregnancies, BMI, insulin level, age, and one target variable.
- It contains 768 data points with nine features each.
20. BBCSport Dataset
Classification is one of the simplest and widespread problems in machine learning. If you are searching for a dataset for your sports classifier, then you came to the right place. This BBCSport dataset is just for you. This dataset is collected from the BBC Sport official website related to sports news articles in five topical areas from 2004-2005.
Features
- You can download pre-processed data or raw text data.
- It Consists of 737 documents.
- This dataset has five predefined classes, i.e., athletics, cricket, football, rugby, tennis.
- The step of pre-processing of this dataset is as follows: stemming, stop-word removal, and low term frequency filtering.
Dataset is an integral part of machine learning applications. It can be available in different formats like .txt, .csv, and many more. In supervised machine learning, the labeled training dataset is used, and in unsupervised, no label is needed. If you are a beginner, we recommend you to read this article thoroughly.
We firmly believe that this article helps to save your valuable time and help you to find out your desired dataset effortlessly. Even if you are not a fresher, we also recommend you to read it. You might be astonished. Why? If you are already a machine learning and AI developer, then you may need these datasets anytime.